JAX 是怎么分配内存的
从 BFC Allocator、预分配和碎片整理入手,解释 JAX 的 GPU 内存管理为什么和 PyTorch 不一样。
引言
在之前的工作中我遇到一个问题:在我们的RL Job里,Jax Trainer跑着跑着OOM了,这很罕见。
我之前大部分的OOM Debug经验都来自Torch——对付Torch的OOM,基本就是两个套路:
- 细致点的话,用Torch Memory Visualizer 把显存占用的来源一点点分析出来,然后针对性优化,很多时候其实是忘记释放或者申请了没有必要的大内存;
- 懒一点的话,在疑似Memory Leak的角落加上
torch.cuda.empty_cache()。
所以碰到Jax OOM这个问题的时候我想到了两个更基本的问题:
- 为什么我很少在Jax中遇到OOM?
- 我能不能使用
jax.cuda.empty_cache()?
想回答这两个问题,就得先搞明白Jax到底是怎么分配内存的——于是就有了这篇blog。
这篇文章也同步分享在知乎:JAX 是怎么分配内存的。
概览
这里我们先通过一张 JAX vs. PyTorch 的对比表,来大致了解 JAX 的内存分配逻辑。我这里假设你已经熟悉 PyTorch 的 memory allocator 是如何工作的;如果还不熟悉,可以先参考这篇文章:A guide to PyTorch’s CUDA Caching Allocator。
| 层级 | JAX | PyTorch |
|---|---|---|
| 用户代码 | jax.Array | torch.Tensor |
| 运行时 | PJRT client | ATen / c10 |
| 分配器 | BFCAllocator(预分配大 Region,Best-Fit + Coalescing) | CUDACachingAllocator(按需 cudaMalloc,free 后缓存进池子) |
| 系统调用 | StreamExecutor -> cuMemAlloc(基本只在启动时) | cudaMalloc / cudaFree(运行中持续发生) |
| 驱动 | CUDA Driver | CUDA Driver |
注:PJRT(Portable JIT Runtime)是 JAX 用来和底层设备后端交互的运行时接口,负责提交编译后的 XLA 程序、管理 device buffer,并调用底层内存分配器。
可以看到,Jax 和 Pytorch的内存管理层级结构上基本一致,主要区别在于Jax的BFCAllocator和Torch的CachingAllocator内在的分配逻辑上有很大的不同。
Jax的BFCAllocator走的是预分配大内存的路线,而Torch的CachingAllocator走的是按需申请内存然后缓存进Caching Pool的路线。
什么是BFC Allocator
BFC是Best-Fit with Coalescing的缩写。这套代码在XLA Github Repo的xla/tsl/framework/bfc_allocator.cc里(tsl是从TensorFlow拆出来的基础库,这套分配器最早是给TF写的,XLA直接继承了过来)。
它是什么、为什么这么设计,源码开头的注释其实已经把话说完了:
// 一个实现了 'best-fit with coalescing'(最佳适配 + 合并)算法的内存分配器。
// 本质上是 Doug Lea 的 malloc(dlmalloc)的一个极简版本。
//
// 这个分配器的目标是通过合并(coalescing)来支持碎片整理。
// 我们的一个前提假设是:使用它的进程几乎拥有全部内存,
// 并且几乎所有的内存分配请求都通过这个接口进行。
class BFCAllocator : public Allocator {
- 这是一个简化版的dlmalloc——所以接下来看到的所有设计(切分Chunk、相邻合并、按大小分桶)在CPU malloc的世界里都有几十年历史了,只是被搬到了GPU显存上。
- 它的核心前提是”这个进程拥有几乎全部内存,且几乎所有分配请求都走我这里”——这样的话,Jax就可以放心地在自己的池子里做切分与合并,从而最大化程度减少碎片化。
它的简化版工作流程是:
- 一开始向GPU一次性要一大片连续内存(默认75%,可以通过环境变量
XLA_PYTHON_CLIENT_MEM_FRACTION控制)。 - 当Jax请求内存时,从空闲的Chunk里找一块大小最接近且够用的(Best-Fit),如果太大就切开(Split),把大小正好的那块给用户。
- 当Jax释放内存时,把这块Chunk标记为空闲,并通过它的prev/next指针检查物理上相邻的前后Chunk是否也空闲——是的话就地合并(Coalescing),从而减少碎片化。
BFC Allocator的详细数据结构
BFC内部就三个核心数据结构:Region、Chunk、Bin。
1. Region:真正从GPU申请来的大片内存区域
class AllocationRegion {
// ...
void* ptr_ = nullptr; // region起始地址
size_t memory_size_ = 0; // region大小
void* end_ptr_ = nullptr; // region结束地址
// 这个数组的大小是memory_size_ / 256B,代表每256B一个槽位,每个槽位存储一个ChunkHandle
// 但只有Chunk起始地址对应的槽位存着有效的ChunkHandle(用户拿到的ptr一定是某个Chunk的起始地址)。
// 这样就能通过ptr以O(1)反查出ChunkHandle,进而在chunks_数组中找到对应的Chunk
std::vector<ChunkHandle> handles_;
};
每个AllocationRegion对应一次SubAllocator::Alloc()调用——也就是一次真正向CUDA要内存的动作。在默认的预分配模式下,整个进程通常只有一个Region,就是启动时拿走的那75%显存。
而handles_数组的主要作用是方便通过ptr来反查出它对应哪个Chunk。用户释放内存时只会丢给BFC一个裸指针(DeallocateRaw(ptr)),BFC必须能从指针反查出它对应哪个Chunk。Region的做法简单粗暴——handles_是一个大数组,每256B一个槽位,用(ptr - base) >> 8直接当下标,O(1)查到ChunkHandle。这也顺便解释了为什么BFC的所有分配都会向上取整到256B的倍数:
static constexpr size_t kMinAllocationBits = 8;
static constexpr size_t kMinAllocationSize = 1 << kMinAllocationBits; // 256B
2. Chunk:内存分配与释放的基本单位
// 一个 Chunk 指向一块内存,这块内存要么整块空闲,要么整块被某一次用户分配占用。
//
// 所有 Chunk 串成一个双向链表,
// prev/next 指针指向物理上紧邻的前后 Chunk。
struct Chunk {
size_t size = 0; // 这块内存的实际大小
size_t requested_size = 0; // 用户真正请求的大小(size >= requested_size)
int64_t allocation_id = -1; // -1表示free,>0表示in use
void* ptr = nullptr; // 内存起始地址
ChunkHandle prev = kInvalidChunkHandle; // 物理上紧邻的前一个Chunk
ChunkHandle next = kInvalidChunkHandle; // 物理上紧邻的后一个Chunk
BinNum bin_num = kInvalidBinNum; // free时所在的Bin编号
bool in_use() const { return allocation_id != -1; }
};
注释把Chunk的性质说得很清楚:一个Region被切成若干Chunk,这些Chunk覆盖整个Region;每个Chunk要么整块free、要么整块被占用,没有中间状态。
而prev/next是按物理地址顺序串起来的双向链表,这就是free memory时做Coalescing的依据:只看左右邻居是否free,能合并就合并,从而创造出更大的chunk以备使用。另外可以注意size和requested_size是分开记录的,源码注释说这是为了追踪”我们多给了用户多少”(即内部碎片),用来评估切分策略是否高效。
3. Bin:空闲Chunk的快速索引
// 一个 Bin 是一组大小相近的空闲 Chunk 的集合。
// 已分配的 Chunk 永远不会出现在 Bin 里。
struct Bin {
// 这个 Bin 里的所有 Chunk 大小都 >= bin_size。
size_t bin_size = 0;
// Bin 内的空闲 Chunk 列表,按 Chunk 大小排序。
FreeChunkSet free_chunks; // absl::btree_set<ChunkHandle, ChunkComparator>
};
class ChunkComparator {
// 先按 size 排序,size 相同时用指针地址作为决胜判据(tie breaker)。
bool operator()(const ChunkHandle ha, const ChunkHandle hb) const
ABSL_NO_THREAD_SAFETY_ANALYSIS {
const Chunk* a = allocator_->ChunkFromHandle(ha);
const Chunk* b = allocator_->ChunkFromHandle(hb);
if (a->size != b->size) {
return a->size < b->size;
}
return a->ptr < b->ptr;
}
如果每次分配都要在所有空闲Chunk里线性扫描找best fit,那就太慢了。所以BFC给空闲Chunk建了一层大小索引:一共21个Bin(kNumBins = 21),第b个Bin负责大小落在[256 << b, 256 << (b+1))区间的空闲Chunk:
Bin 0: [256B, 512B)
Bin 1: [512B, 1KB)
...
Bin 19: [128MB, 256MB)
Bin 20: >= 256MB
每个Bin内部是一个有序set(absl::btree_set),排序规则写在ChunkComparator的注释里:
先按size从小到大,size相同再按地址从低到高。于是”Best-Fit”的实现水到渠成:从目标Bin开始往更大的Bin方向找,在有序set里碰到的第一个够大的Chunk,就是全局最小且够用的那个。
最后注意注释里的另一句话:”Allocated chunks are never in a Bin”——Bin只索引空闲的Chunk。Chunk被分配出去时会从Bin里摘除(bin_num置为kInvalidBinNum),释放并合并后再重新放入对应大小匹配的Bin。
三者的关系
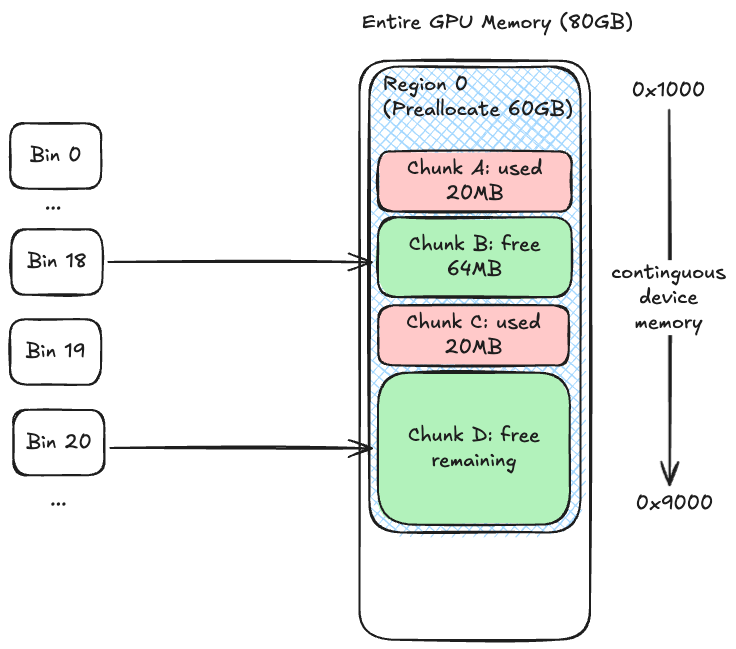
-
Region 是地址空间视角:
首先我们看到蓝色阴影的大方块,代表的Jax向GPU第一次申请的大块连续内存,0x1000 和 0x9000分别代表这个Region的起始和结束指针位置(当然这个地址编号不严谨,只是粗略表示)
-
Chunk 是物理布局视角:
每个Region里有很多连续的Chunk,他们可以是Free或者used状态。他们根据大小隶属于不同的Bin
-
Bin 是空闲块索引视角:
Bin实际上只参与Free Chunk的索引,并且按照大小组织起来,分配时,BFC会根据从小到大的顺序从Bin里挑选一个最小单足够大的Free Chunk,这就是Best Fit的核心。
BFC Allocator的API
理解了三个数据结构后,我们来看分配和释放到底是怎么在它们之间发生的。先看分配的主线入口AllocateRaw,再拆解它沿途用到的三个基础操作:Extend(扩池)、SplitChunk(切分)、Merge(合并)。
1. 分配主线:AllocateRaw → FindChunkPtr
AllocateRaw是用户侧(经由 PJRT)真正调用的入口。核心逻辑在AllocateRawInternal里,它的主线非常短——先把请求大小向上取整到 256B、算出该去哪个 Bin 找,然后就是”找不到就扩大Region、扩完再找”:
void* BFCAllocator::AllocateRawInternal(size_t alignment, size_t num_bytes, ...) {
size_t rounded_bytes = RoundedBytes(num_bytes); // 向上取整到256B的倍数
BinNum bin_num = BinNumForSize(rounded_bytes); // 落到哪个Bin
absl::MutexLock l(mutex_);
// 1. 先在现有的空闲Chunk里找一块够用的
void* ptr = FindChunkPtr(bin_num, rounded_bytes, num_bytes, alignment, ...);
if (ptr != nullptr) return ptr;
// 2. 找不到 → Extend()向底层要一块大的,再找一次
if (Extend(alignment, rounded_bytes)) {
ptr = FindChunkPtr(bin_num, rounded_bytes, num_bytes, alignment, ...);
if (ptr != nullptr) return ptr;
}
// 3. 还是不行 → 回收空闲region,最终仍失败就是OOM
// ...
}
真正干活的是FindChunkPtr,它就是 Best-Fit 的实现。注意它怎么利用前面 Bin 的两个性质——Bin 之间按大小递增、Bin 内部按 size 从小到大排序:
void* BFCAllocator::FindChunkPtr(BinNum bin_num, size_t rounded_bytes,
size_t num_bytes, size_t alignment, ...) {
// 从目标Bin开始,向更大的Bin方向扫描
for (; bin_num < kNumBins; bin_num++) {
Bin* b = BinFromIndex(bin_num);
// Bin内是按size升序的有序set,第一个装得下的就是这个Bin里最小够用的
for (auto citer = b->free_chunks.begin(); citer != b->free_chunks.end();
++citer) {
ChunkHandle h = (*citer);
Chunk* chunk = ChunkFromHandle(h);
if (chunk->size >= rounded_bytes /* + 对齐padding */) {
// 先把它从空闲Bin里摘掉
RemoveFreeChunkIterFromBin(&b->free_chunks, citer);
// 如果这块远大于所需,就Split(见下面的SplitChunk)
if (chunk->size >= rounded_bytes * 2 || /* 剩余超过128MB */) {
SplitChunk(h, rounded_bytes);
chunk = ChunkFromHandle(h);
}
chunk->requested_size = num_bytes;
chunk->allocation_id = next_allocation_id_++; // 标记为in use
return chunk->ptr;
}
}
}
return nullptr; // 所有Bin都找不到 → 交回上层去Extend()
}
把两段连起来,整条分配主线就是:
AllocateRaw(num_bytes)
└─ rounded_bytes = 向上取整到256B
└─ bin_num = 该去哪个Bin
└─ FindChunkPtr:从 bin_num 往大Bin扫,取第一个够大的空闲Chunk(Best-Fit)
├─ 命中:摘出Bin → 太大就Split → 标记in_use → 返回ptr
└─ 没命中:返回nullptr
└─ Extend():向底层要一块大内存,生成一个巨大的空闲Chunk
└─ 再FindChunkPtr一次(这次必然命中)
为什么这样就是”全局最小且够用”?因为扫描从目标 Bin 开始向更大的 Bin 走,而每个 Bin 内部又按 size 升序排列——所以第一个碰到的够大的 Chunk,必然是当前所有空闲 Chunk 里能装下这次请求、且体积最小的那个。这正是 Best-Fit 的定义。
下面就把这条主线上的三个关键操作Extend、SplitChunk、Merge分别展开。
2. Extend:向底层要一块大内存
Extend()是Region级别的操作,不是扩展某个Chunk,而是给整个BFCAllocator补充内存。它只在Region里找不到足够大的空闲Chunk时才被调用(默认的preallocate模式下基本只有第一次分配会触发它)。
bool BFCAllocator::Extend(size_t alignment, size_t rounded_bytes) {
size_t available_bytes = memory_limit_ - *stats_.pool_bytes;
available_bytes = (available_bytes / kMinAllocationSize) * kMinAllocationSize;
if (rounded_bytes > available_bytes) {
return false; // 预算上限不够的话(比如硬件上限),直接失败
}
// 不够就按2的幂往上翻,直到能装下这次请求
bool increased_allocation = false;
while (rounded_bytes > curr_region_allocation_bytes_) {
curr_region_allocation_bytes_ *= 2;
increased_allocation = true;
}
size_t bytes = std::min(curr_region_allocation_bytes_, available_bytes);
size_t bytes_received;
void* mem_addr = sub_allocator_->Alloc(alignment, bytes, &bytes_received);
// ... 如果Alloc失败,按0.9的系数不断回退重试 ...
拿到内存后,关键的一步是:把整块新内存包装成一个大的空闲Chunk,然后丢进对应的Bin里。
// 把整块新内存先包成一个大的 Chunk,后续再按需切分。
ChunkHandle h = AllocateChunk();
BFCAllocator::Chunk* c = ChunkFromHandle(h);
c->ptr = mem_addr;
c->size = bytes_received;
c->allocation_id = -1; // -1 表示空闲
c->prev = kInvalidChunkHandle;
c->next = kInvalidChunkHandle;
region_manager_.set_handle(c->ptr, h);
// 可能和相邻region合并,并把这个大Chunk插进对应Bin
InsertFreeChunkIntoBin(TryToCoalesce(h, /*ignore_freed_at=*/false));
所以在preallocate 75%的常见路径下,第一次Extend()之后的状态就是:一个Region,里面一个覆盖全部内存的巨大空闲Chunk,挂在最大的Bin 20上。后面所有的分配都是从这个大Chunk上”切”出来的。
3. SplitChunk:把大Chunk切成两块
当FindChunkPtr找到一个比请求大不少的空闲Chunk时,它不会整块给用户,而是调用SplitChunk()切出用户需要的大小,剩下的部分变成一个新的空闲Chunk。
void BFCAllocator::SplitChunk(BFCAllocator::ChunkHandle h, size_t num_bytes) {
ChunkHandle h_new_chunk = AllocateChunk();
Chunk* c = ChunkFromHandle(h);
CHECK(!c->in_use() && (c->bin_num == kInvalidBinNum));
// 新Chunk从 c->ptr + num_bytes 处开始
BFCAllocator::Chunk* new_chunk = ChunkFromHandle(h_new_chunk);
new_chunk->ptr = static_cast<void*>(static_cast<char*>(c->ptr) + num_bytes);
region_manager_.set_handle(new_chunk->ptr, h_new_chunk);
new_chunk->size = c->size - num_bytes; // 剩余部分
c->size = num_bytes; // 前半段缩小到请求大小
new_chunk->allocation_id = -1;
// 维护物理相邻链表: c <-> neighbor 变成 c <-> new_chunk <-> neighbor
BFCAllocator::ChunkHandle h_neighbor = c->next;
new_chunk->prev = h;
new_chunk->next = h_neighbor;
c->next = h_new_chunk;
if (h_neighbor != kInvalidChunkHandle) {
Chunk* c_neighbor = ChunkFromHandle(h_neighbor);
c_neighbor->prev = h_new_chunk;
}
InsertFreeChunkIntoBin(h_new_chunk); // 剩余部分作为新空闲Chunk入Bin
}
这里要注意两点:第一,切分只是改size和prev/next指针,并没有移动任何真实内存;第二,切出来的余量会立刻作为一个独立的空闲Chunk插回Bin,供后续分配复用。
那什么时候才切?逻辑写在FindChunkPtr里——只有当余量足够大(默认请求的2倍以上,或剩余超过128MB)时才切,否则宁可整块给出去,多给的部分算作内部碎片:
const int64_t max_internal_fragmentation_bytes =
(opts_.fragmentation_fraction > 0.0)
? opts_.fragmentation_fraction * memory_limit_
: 128 << 20; // 默认128MB
if (chunk->size >= rounded_bytes * 2 ||
static_cast<int64_t>(chunk->size) - rounded_bytes >=
max_internal_fragmentation_bytes) {
SplitChunk(h, rounded_bytes);
}
4. Merge:把相邻的空闲Chunk合并
Merge()是Split的逆操作,也是名字里”Coalescing”的由来。它把两个物理相邻的空闲Chunk合并成一个:
void BFCAllocator::Merge(BFCAllocator::ChunkHandle h1,
BFCAllocator::ChunkHandle h2) {
Chunk* c1 = ChunkFromHandle(h1);
Chunk* c2 = ChunkFromHandle(h2);
CHECK(!c1->in_use() && !c2->in_use()); // 两块都必须空闲
// 处理邻居链表: c1 <-> c2 <-> c3 合并成 c1 <-> c3
BFCAllocator::ChunkHandle h3 = c2->next;
c1->next = h3;
if (h3 != kInvalidChunkHandle) {
ChunkFromHandle(h3)->prev = h1;
}
c1->size += c2->size; // c1 吞并 c2 的大小
DeleteChunk(h2); // c2 的metadata被回收
}
但Merge()自己不判断”邻居在不在、能不能合”,这个决策在TryToCoalesce()里——它顺着prev/next分别看物理上的前后邻居,只要是空闲的就先从Bin里摘掉再合并:
BFCAllocator::ChunkHandle BFCAllocator::TryToCoalesce(ChunkHandle h, ...) {
Chunk* c = ChunkFromHandle(h);
ChunkHandle coalesced_chunk = h;
// 右邻居空闲 → 合并进来
if (c->next != kInvalidChunkHandle && !ChunkFromHandle(c->next)->in_use()) {
RemoveFreeChunkFromBin(c->next);
Merge(h, c->next);
}
// 前邻居空闲 → 把自己合并进去
if (c->prev != kInvalidChunkHandle && !ChunkFromHandle(c->prev)->in_use()) {
coalesced_chunk = c->prev;
RemoveFreeChunkFromBin(c->prev);
Merge(c->prev, h);
}
return coalesced_chunk;
}
注意合并判断的依据是物理相邻(prev/next),而不是”在不在同一个Bin”。两个分属不同Bin、大小完全不同的空闲Chunk,只要地址上挨着,就能合并成一个更大的Chunk重新入Bin。
结论
看到这里,Jax的内存分配机制应该非常清晰了,让我们来回答一开始的两个问题,
-
为什么我们很少在Jax中遇到OOM
原因有两层。第一层在编译期:Jax的计算是先经过XLA静态编译再执行的,XLA在编译时有一个Buffer Assignment阶段,会把计算图里所有中间结果的内存提前规划好。也就是说一个jit过的程序,它的峰值内存在编译完成时就已经确定了——如果显存放不下,问题会在编译或首次执行时就暴露出来,而不是像Torch那样跑到第N个step才因为运行时动态分配(外加碎片化)突然炸掉。
第二层在分配器:Jax默认会在backend初始化时(差不多是第一次真正用到GPU的时候,而不是严格意义上的
import jax)一次性向CUDA申请75%的显存(由XLA_PYTHON_CLIENT_MEM_FRACTION控制)作为一个大Region,之后所有的allocate/deallocate都只是BFC Allocator在这个Region内部切分与合并Chunk。所以对nvidia-smi来说,进程的显存占用从头到尾稳定在75%,不存在运行中途向驱动要内存却要不到的情况。 -
我能不能jax.cuda.empty_cache()
没有这个API,也不需要。先想清楚
torch.cuda.empty_cache()到底干了什么:它是把Caching Allocator里”已经free但还缓存着没归还给CUDA”的block还给驱动,好让同一张卡上的其他进程或库能用上这部分显存——它并不能解决Torch进程内部的碎片化。而在Jax的默认模式下,那75%的Region是预分配的、整个进程生命周期都由BFC Allocator持有,本来就没打算还给驱动,所以”empty cache”这个动作没有对象。至于碎片化,BFC在free时会自动通过prev/next指针把相邻的空闲Chunk合并(这就是名字里的Coalescing),不需要手动干预。如果你真的需要Jax把显存让出来(比如要和别的进程共享一张卡),正确的做法是设置
XLA_PYTHON_CLIENT_PREALLOCATE=false或XLA_PYTHON_CLIENT_ALLOCATOR=platform让它按需分配——但这是拿性能换灵活性,一般只在debug时用。