How JAX Allocates Memory
A deep dive into JAX GPU memory allocation, BFCAllocator preallocation, and how it differs from PyTorch caching.
Intro
At my previous job I ran into a problem: our JAX trainer in an RL job would OOM after running for a while, which is pretty rare.
Most of my OOM debugging experience came from Torch, where there are basically two moves:
- The careful way: use the Torch Memory Visualizer to break down where memory goes and optimize from there. Often it’s just a tensor you forgot to free, or an allocation that was bigger than it needed to be.
- The lazy way: sprinkle
torch.cuda.empty_cache()around wherever you suspect a leak.
So when I hit the JAX OOM, two more basic questions came to mind:
- Why do I rarely hit OOM in JAX?
- Can I call
jax.cuda.empty_cache()?
To answer them I had to first understand how JAX actually allocates memory, and that’s how this post came about.
Overview
Let’s start with a JAX vs. PyTorch comparison table to get a rough feel for how JAX handles memory. I’m assuming you already know how PyTorch’s memory allocator works; if not, A guide to PyTorch’s CUDA Caching Allocator is a great read.
| Layer | JAX | PyTorch |
|---|---|---|
| User code | jax.Array | torch.Tensor |
| Runtime | PJRT client | ATen / c10 |
| Allocator | BFCAllocator (preallocates a big Region, Best-Fit + Coalescing) | CUDACachingAllocator (on-demand cudaMalloc, cached into a pool after free) |
| Syscall | StreamExecutor -> cuMemAlloc (basically only at startup) | cudaMalloc / cudaFree (keeps happening at runtime) |
| Driver | CUDA Driver | CUDA Driver |
Note: PJRT (Portable JIT Runtime) is the runtime interface JAX uses to talk to the device backend. It submits compiled XLA programs, manages device buffers, and calls into the underlying allocator.
The layering is basically the same on both sides. The real difference is in the allocator: JAX’s BFCAllocator vs Torch’s CachingAllocator behave quite differently under the hood.
JAX’s BFCAllocator preallocates one big chunk of memory upfront, while Torch’s CachingAllocator allocates on demand and caches freed blocks into a pool for reuse.
What is the BFC Allocator
BFC stands for Best-Fit with Coalescing. The code lives at xla/tsl/framework/bfc_allocator.cc in the XLA GitHub repo (tsl is the base library split out of TensorFlow; this allocator was originally written for TF, and XLA inherited it as-is).
What it is and why it’s designed this way is pretty much spelled out in the comment at the top of the source:
// A memory allocator that implements a 'best-fit with coalescing'
// algorithm. This is essentially a very simple version of Doug Lea's
// malloc (dlmalloc).
//
// The goal of this allocator is to support defragmentation via
// coalescing. One assumption we make is that the process using this
// allocator owns pretty much all of the memory, and that nearly
// all requests to allocate memory go through this interface.
class BFCAllocator : public Allocator {
Two takeaways:
- It’s a simplified dlmalloc — so everything you’re about to see (splitting chunks, merging neighbors, bucketing by size) has decades of history in the CPU malloc world. It’s just been moved onto GPU memory.
- The core assumption is “this process owns almost all the memory, and nearly all allocations go through me” — which is exactly what lets JAX freely split and merge inside its own pool to keep fragmentation low.
The simplified workflow is:
- Grab one big contiguous block of GPU memory upfront (75% by default, controlled by the
XLA_PYTHON_CLIENT_MEM_FRACTIONenv var). - On an allocation request, find a free chunk that’s the smallest one that still fits (Best-Fit), and if it’s too big, split it and hand back the right-sized piece.
- On a free, mark the chunk as free and use its prev/next pointers to check whether the physically adjacent chunks are also free — if so, merge them in place (Coalescing) to reduce fragmentation.
The data structures inside the BFC Allocator
There are only three core data structures: Region, Chunk, and Bin.
1. Region: the big block actually requested from the GPU
class AllocationRegion {
// ...
void* ptr_ = nullptr; // region start address
size_t memory_size_ = 0; // region size
void* end_ptr_ = nullptr; // region end address
// Size is memory_size_ / 256B, i.e. one slot per 256B, each holding a ChunkHandle.
// Only the slot at a chunk's start address holds a valid ChunkHandle (the ptr a
// user gets back is always a chunk's start address).
// This lets us reverse-look-up a ChunkHandle from a ptr in O(1), and then find
// the corresponding Chunk in the chunks_ array.
std::vector<ChunkHandle> handles_;
};
Each AllocationRegion corresponds to one SubAllocator::Alloc() call — one actual request to CUDA for memory. In the default preallocate mode there’s usually just one Region for the whole process: that 75% of VRAM grabbed at startup.
The main job of handles_ is to reverse-look-up which Chunk a ptr belongs to. When a user frees memory they only hand BFC a raw pointer (DeallocateRaw(ptr)), and BFC has to figure out which Chunk it maps to. The Region’s approach is brute-force but effective: handles_ is a big array with one slot per 256B, and (ptr - base) >> 8 is used directly as the index to get the ChunkHandle in O(1). This also explains why every BFC allocation is rounded up to a multiple of 256B:
static constexpr size_t kMinAllocationBits = 8;
static constexpr size_t kMinAllocationSize = 1 << kMinAllocationBits; // 256B
2. Chunk: the basic unit of allocation and free
// A Chunk points to a piece of memory that's either entirely free or entirely
// in use by one user memory allocation.
//
// Chunks participate in a doubly-linked list,
// and the prev/next pointers point to the physically adjacent chunks.
struct Chunk {
size_t size = 0; // actual size of this piece of memory
size_t requested_size = 0; // size the user actually asked for (size >= requested_size)
int64_t allocation_id = -1; // -1 means free, > 0 means in use
void* ptr = nullptr; // start address
ChunkHandle prev = kInvalidChunkHandle; // physically preceding chunk
ChunkHandle next = kInvalidChunkHandle; // physically following chunk
BinNum bin_num = kInvalidBinNum; // which Bin it's in when free
bool in_use() const { return allocation_id != -1; }
};
The comment says it well: a Region is split into a number of Chunks that cover the whole Region, and each Chunk is either entirely free or entirely in use — there’s no in-between state.
prev/next form a doubly-linked list in physical address order, which is the basis for coalescing on free: just look at whether the left/right neighbors are free, and merge if so, creating a bigger chunk for later. Also note that size and requested_size are tracked separately — the source comment says this is to track “how much extra we handed the user” (i.e. internal fragmentation), to gauge how efficient the splitting strategy is.
3. Bin: a fast index of free Chunks
// A Bin is a collection of similar-sized free chunks.
// Allocated chunks are never in a Bin.
struct Bin {
// All chunks in this bin have >= bin_size memory.
size_t bin_size = 0;
// List of free chunks within the bin, sorted by chunk size.
FreeChunkSet free_chunks; // absl::btree_set<ChunkHandle, ChunkComparator>
};
class ChunkComparator {
// Sort first by size and then use pointer address as a tie breaker.
bool operator()(const ChunkHandle ha, const ChunkHandle hb) const
ABSL_NO_THREAD_SAFETY_ANALYSIS {
const Chunk* a = allocator_->ChunkFromHandle(ha);
const Chunk* b = allocator_->ChunkFromHandle(hb);
if (a->size != b->size) {
return a->size < b->size;
}
return a->ptr < b->ptr;
}
Linearly scanning every free chunk for a best fit on each allocation would be too slow. So BFC builds a size index over free chunks: there are 21 Bins (kNumBins = 21), and Bin b holds free chunks whose size falls in [256 << b, 256 << (b+1)):
Bin 0: [256B, 512B)
Bin 1: [512B, 1KB)
...
Bin 19: [128MB, 256MB)
Bin 20: >= 256MB
Each Bin is a sorted set (absl::btree_set), with the ordering defined in ChunkComparator: first by size ascending, then by address ascending for ties. This makes “Best-Fit” fall out naturally: start at the target Bin and scan toward larger Bins, and the first chunk big enough in the sorted set is the globally smallest one that fits.
One more thing from the comment: “Allocated chunks are never in a Bin” — Bins only index free chunks. When a chunk is handed out it’s removed from its Bin (bin_num set to kInvalidBinNum), and after being freed and merged it’s reinserted into the Bin matching its size.
How the three relate
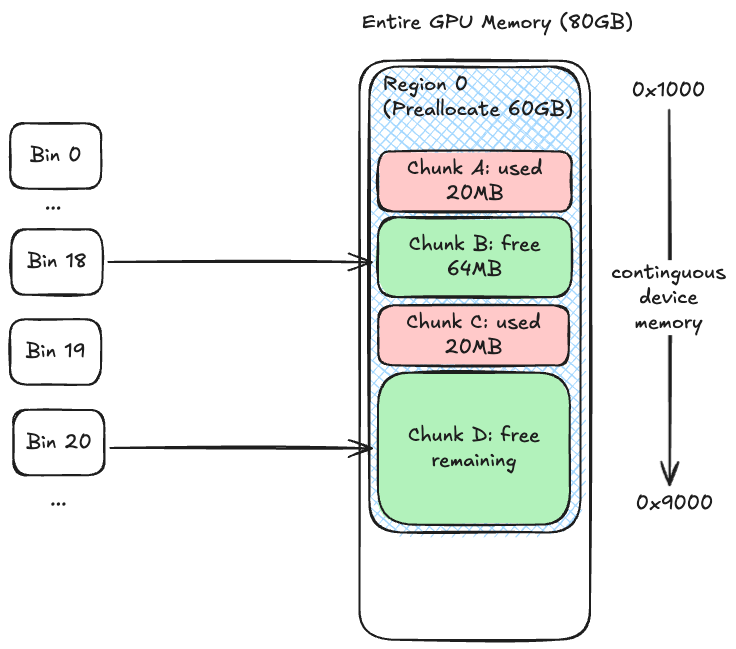
-
Region is the address-space view.
The big shaded block is the large contiguous chunk JAX first requested from the GPU.
0x1000and0x9000mark the Region’s start and end pointers (the numbers aren’t meant to be precise, just illustrative). -
Chunk is the physical-layout view.
A Region contains many contiguous Chunks, each either free or in use. Free ones belong to different Bins based on size.
-
Bin is the free-block index view.
Bins only index free Chunks, organized by size. On allocation, BFC scans from smaller to larger Bins to pick the smallest free Chunk that still fits — the heart of Best-Fit.
The BFC Allocator’s APIs
Now that we have the three data structures, let’s see how allocation and free actually happen across them. We’ll look at the allocation entry point AllocateRaw first, then break down the three building blocks it uses along the way: Extend (grow the pool), SplitChunk (split), and Merge (merge).
1. The allocation path: AllocateRaw → FindChunkPtr
AllocateRaw is what the user side (via PJRT) actually calls. The core logic lives in AllocateRawInternal, and the main path is short — round the request up to 256B, figure out which Bin to search, then “if you can’t find one, grow the region and search again”:
void* BFCAllocator::AllocateRawInternal(size_t alignment, size_t num_bytes, ...) {
size_t rounded_bytes = RoundedBytes(num_bytes); // round up to a multiple of 256B
BinNum bin_num = BinNumForSize(rounded_bytes); // which Bin to start from
absl::MutexLock l(mutex_);
// 1. First, look for a free chunk that fits among existing ones
void* ptr = FindChunkPtr(bin_num, rounded_bytes, num_bytes, alignment, ...);
if (ptr != nullptr) return ptr;
// 2. Not found -> Extend() to grab a big block, then search again
if (Extend(alignment, rounded_bytes)) {
ptr = FindChunkPtr(bin_num, rounded_bytes, num_bytes, alignment, ...);
if (ptr != nullptr) return ptr;
}
// 3. Still nothing -> reclaim free regions; if it still fails, that's an OOM
// ...
}
The real work happens in FindChunkPtr, which is the Best-Fit implementation. Notice how it leans on the two Bin properties from earlier — Bins are ordered by increasing size, and within a Bin chunks are sorted by size ascending:
void* BFCAllocator::FindChunkPtr(BinNum bin_num, size_t rounded_bytes,
size_t num_bytes, size_t alignment, ...) {
// Start at the target Bin and scan toward larger Bins
for (; bin_num < kNumBins; bin_num++) {
Bin* b = BinFromIndex(bin_num);
// A Bin is a size-ascending sorted set; the first one that fits is the
// smallest sufficient chunk in this Bin
for (auto citer = b->free_chunks.begin(); citer != b->free_chunks.end();
++citer) {
ChunkHandle h = (*citer);
Chunk* chunk = ChunkFromHandle(h);
if (chunk->size >= rounded_bytes /* + alignment padding */) {
// Hit: pull it out of the free Bin first
RemoveFreeChunkIterFromBin(&b->free_chunks, citer);
// If it's much larger than needed, split it (see SplitChunk below)
if (chunk->size >= rounded_bytes * 2 || /* leftover > 128MB */) {
SplitChunk(h, rounded_bytes);
chunk = ChunkFromHandle(h);
}
chunk->requested_size = num_bytes;
chunk->allocation_id = next_allocation_id_++; // mark as in use
return chunk->ptr;
}
}
}
return nullptr; // no Bin has one -> hand back to the caller to Extend()
}
Putting the two together, the whole allocation path is:
AllocateRaw(num_bytes)
└─ rounded_bytes = round up to 256B
└─ bin_num = which Bin to start from
└─ FindChunkPtr: scan from bin_num toward larger Bins, take the first free chunk that fits (Best-Fit)
├─ hit: pull out of Bin → split if too big → mark in_use → return ptr
└─ miss: return nullptr
└─ Extend(): grab a big block from below, creating one huge free chunk
└─ FindChunkPtr again (guaranteed to hit this time)
Why is this “globally smallest that still fits”? Because the scan starts at the target Bin and moves toward larger Bins, and each Bin is sorted by size ascending — so the first chunk big enough that we hit is necessarily the smallest free chunk that can hold this request. That’s the definition of Best-Fit.
Now let’s break down the three key operations on this path: Extend, SplitChunk, and Merge.
2. Extend: grab a big block from below
Extend() is a Region-level operation. It doesn’t extend some Chunk; it adds memory to the whole BFCAllocator. It’s only called when no free Chunk in the Region is big enough (in the default preallocate mode, basically only the first allocation triggers it).
bool BFCAllocator::Extend(size_t alignment, size_t rounded_bytes) {
size_t available_bytes = memory_limit_ - *stats_.pool_bytes;
available_bytes = (available_bytes / kMinAllocationSize) * kMinAllocationSize;
if (rounded_bytes > available_bytes) {
return false; // even the budget cap (e.g. hardware limit) isn't enough -> fail
}
// Not enough? double it (power of two) until it can hold this request
bool increased_allocation = false;
while (rounded_bytes > curr_region_allocation_bytes_) {
curr_region_allocation_bytes_ *= 2;
increased_allocation = true;
}
size_t bytes = std::min(curr_region_allocation_bytes_, available_bytes);
size_t bytes_received;
void* mem_addr = sub_allocator_->Alloc(alignment, bytes, &bytes_received);
// ... if Alloc fails, back off by a factor of 0.9 and keep retrying ...
Once it has the memory, the key step is to wrap the whole new block into one big free Chunk and drop it into the right Bin:
// Create one large chunk for the whole memory space that will
// be chunked later.
ChunkHandle h = AllocateChunk();
BFCAllocator::Chunk* c = ChunkFromHandle(h);
c->ptr = mem_addr;
c->size = bytes_received;
c->allocation_id = -1; // -1 means free
c->prev = kInvalidChunkHandle;
c->next = kInvalidChunkHandle;
region_manager_.set_handle(c->ptr, h);
// possibly coalesce with an adjacent region, then insert this big Chunk into its Bin
InsertFreeChunkIntoBin(TryToCoalesce(h, /*ignore_freed_at=*/false));
So on the common preallocate-75% path, the state right after the first Extend() is: one Region containing one huge free Chunk that covers all of it, sitting in the largest Bin 20. Every later allocation is “cut” out of this big Chunk.
3. SplitChunk: cut a big Chunk into two
When FindChunkPtr finds a free Chunk that’s noticeably bigger than the request, it doesn’t hand over the whole thing. It calls SplitChunk() to carve out the requested size, and the leftover becomes a new free Chunk.
void BFCAllocator::SplitChunk(BFCAllocator::ChunkHandle h, size_t num_bytes) {
ChunkHandle h_new_chunk = AllocateChunk();
Chunk* c = ChunkFromHandle(h);
CHECK(!c->in_use() && (c->bin_num == kInvalidBinNum));
// New chunk starts at c->ptr + num_bytes
BFCAllocator::Chunk* new_chunk = ChunkFromHandle(h_new_chunk);
new_chunk->ptr = static_cast<void*>(static_cast<char*>(c->ptr) + num_bytes);
region_manager_.set_handle(new_chunk->ptr, h_new_chunk);
new_chunk->size = c->size - num_bytes; // the leftover
c->size = num_bytes; // shrink the front half to the request size
new_chunk->allocation_id = -1;
// Maintain the physical-neighbor list: c <-> neighbor becomes c <-> new_chunk <-> neighbor
BFCAllocator::ChunkHandle h_neighbor = c->next;
new_chunk->prev = h;
new_chunk->next = h_neighbor;
c->next = h_new_chunk;
if (h_neighbor != kInvalidChunkHandle) {
Chunk* c_neighbor = ChunkFromHandle(h_neighbor);
c_neighbor->prev = h_new_chunk;
}
InsertFreeChunkIntoBin(h_new_chunk); // leftover goes back into a Bin as a new free Chunk
}
Two things to note: first, splitting only changes size and the prev/next pointers — no real memory is moved; second, the leftover is immediately reinserted into a Bin as an independent free Chunk, ready to be reused by later allocations.
So when does it split? The logic is in FindChunkPtr — only when the leftover is large enough (by default, the chunk is at least 2x the request, or the leftover exceeds 128MB). Otherwise it just hands over the whole chunk and counts the extra as internal fragmentation:
const int64_t max_internal_fragmentation_bytes =
(opts_.fragmentation_fraction > 0.0)
? opts_.fragmentation_fraction * memory_limit_
: 128 << 20; // 128MB by default
if (chunk->size >= rounded_bytes * 2 ||
static_cast<int64_t>(chunk->size) - rounded_bytes >=
max_internal_fragmentation_bytes) {
SplitChunk(h, rounded_bytes);
}
4. Merge: coalesce adjacent free Chunks
Merge() is the inverse of Split, and the source of the “Coalescing” in the name. It merges two physically adjacent free Chunks into one:
void BFCAllocator::Merge(BFCAllocator::ChunkHandle h1,
BFCAllocator::ChunkHandle h2) {
Chunk* c1 = ChunkFromHandle(h1);
Chunk* c2 = ChunkFromHandle(h2);
CHECK(!c1->in_use() && !c2->in_use()); // both must be free
// Fix the neighbor list: c1 <-> c2 <-> c3 becomes c1 <-> c3
BFCAllocator::ChunkHandle h3 = c2->next;
c1->next = h3;
if (h3 != kInvalidChunkHandle) {
ChunkFromHandle(h3)->prev = h1;
}
c1->size += c2->size; // c1 absorbs c2's size
DeleteChunk(h2); // c2's metadata is reclaimed
}
But Merge() doesn’t decide “is there a neighbor, can we merge it” itself — that decision is in TryToCoalesce(), which follows prev/next to check the physical neighbors on each side, and if a neighbor is free, pulls it out of its Bin first and then merges:
BFCAllocator::ChunkHandle BFCAllocator::TryToCoalesce(ChunkHandle h, ...) {
Chunk* c = ChunkFromHandle(h);
ChunkHandle coalesced_chunk = h;
// next neighbor is free -> merge it in
if (c->next != kInvalidChunkHandle && !ChunkFromHandle(c->next)->in_use()) {
RemoveFreeChunkFromBin(c->next);
Merge(h, c->next);
}
// prev neighbor is free -> merge self into it
if (c->prev != kInvalidChunkHandle && !ChunkFromHandle(c->prev)->in_use()) {
coalesced_chunk = c->prev;
RemoveFreeChunkFromBin(c->prev);
Merge(c->prev, h);
}
return coalesced_chunk;
}
Note that the merge decision is based on physical adjacency (prev/next), not “are they in the same Bin.” Two free Chunks in different Bins with completely different sizes can still merge into one bigger Chunk (and get reinserted into a Bin) as long as they sit next to each other in address space.
Conclusion
By now the way JAX allocates memory should be pretty clear. Let’s answer the two questions we started with.
-
Why do we rarely hit OOM in JAX?
There are two layers. The first is at compile time: JAX computations are statically compiled by XLA before they run, and XLA has a Buffer Assignment pass that plans out memory for all intermediate results in the graph ahead of time. In other words, a jit-compiled program’s peak memory is already determined once compilation finishes — if it won’t fit, the problem shows up at compile or first execution, not like Torch where it blows up at step N because of runtime dynamic allocation (plus fragmentation).
The second layer is the allocator: by default JAX grabs 75% of VRAM (controlled by
XLA_PYTHON_CLIENT_MEM_FRACTION) from CUDA at backend init (roughly the first time the GPU is actually used, not strictly atimport jax) as one big Region. After that, every allocate/deallocate is just the BFC Allocator splitting and merging Chunks inside that Region. So to nvidia-smi, the process’s memory usage stays steady at 75% the whole time — there’s no situation where it asks the driver for memory mid-run and can’t get it. -
Can I call
jax.cuda.empty_cache()?There’s no such API, and you don’t need one. First, think about what
torch.cuda.empty_cache()actually does: it returns blocks that are “already freed but still cached, not handed back to CUDA” to the driver, so other processes or libraries on the same card can use that memory — it does not fix fragmentation inside the Torch process. In JAX’s default mode, that 75% Region is preallocated and held by the BFC Allocator for the entire process lifetime; it was never meant to be returned to the driver, so “empty cache” has nothing to act on. As for fragmentation, BFC automatically merges adjacent free Chunks on free via prev/next pointers (that’s the Coalescing in the name) — no manual intervention needed.If you genuinely need JAX to give memory back (e.g. to share a card with another process), the right way is to set
XLA_PYTHON_CLIENT_PREALLOCATE=falseorXLA_PYTHON_CLIENT_ALLOCATOR=platformso it allocates on demand — but that trades performance for flexibility, and is usually only worth it when debugging.