Efficient RL Training - Optimizing Weight Sync in slime
A look at how slime synchronizes weights between training and rollout engines, and where the main performance wins come from.

Authored by
Biao He

Zilin Zhu
Ji Li
1. What is slime?
slime is a LLM post-training framework aiming for RL Scaling, it was designed to be:
- Versatile – with a fully customizable rollout interface and flexible training setups (colocated or decoupled, synchronous or asynchronous, RL or SFT cold start).
- Performant - integrating SGLang for inference and Megatron-LM for training, natively.
- Maintainable - with a lightweight codebase and smooth transition from Megatron pretraining to SGLang deployment.1
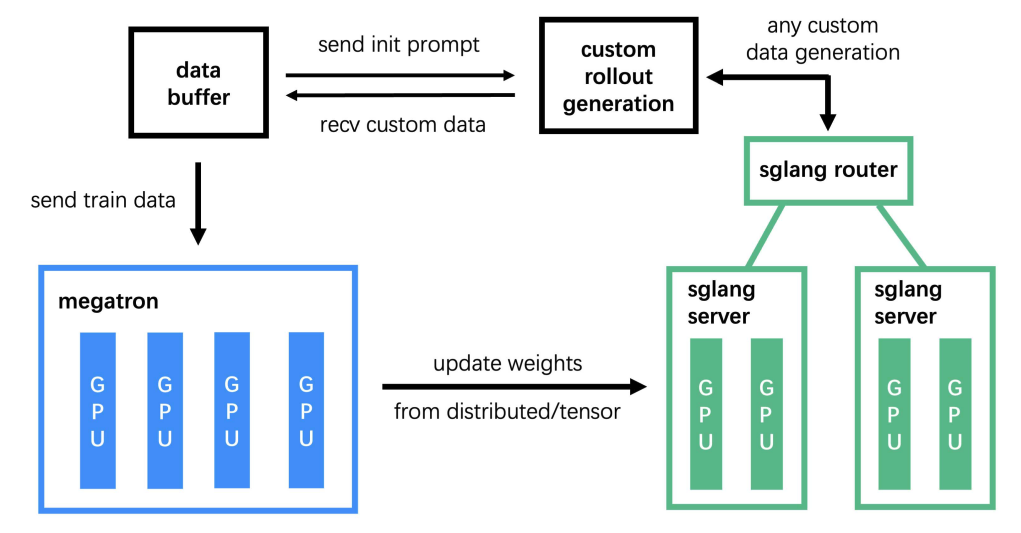
The system consists of three core modules2:
- Training (Megatron) – handles the main training process, reads data from the Data Buffer, and synchronizes parameters with the rollout module after training
- Rollout (SGLang + Router) – generates new data, including rewards and verifier outputs, and writes it to the Data Buffer
- Data Buffer – serves as a bridge module that manages prompt initialization, custom data, and rollout generation strategies.
2. What is Weight Sync?
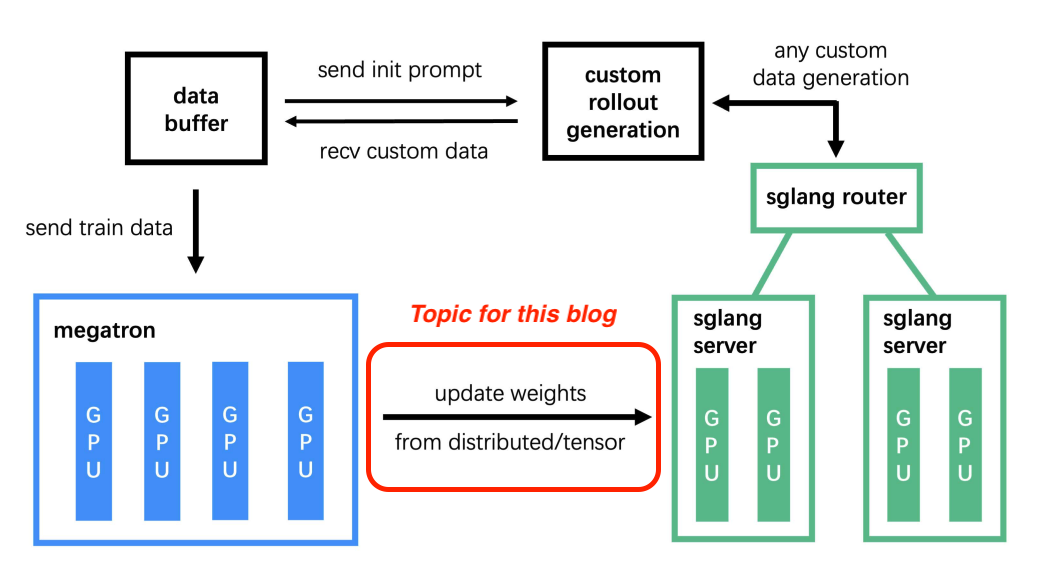
Weight sync in LLM reinforcement learning (RL) refers to the process of copying updated model weights from the training side to the inference side so that inference workers always use up-to-date parameters.
Why do we need it?
In RL for LLMs (e.g., PPO, GRPO):
- Training engine updates weights every optimization step.
- Inference engine generates rollouts, samples actions, but it needs to use the latest policy weights to stay consistent with training.
- These two components often run separately (different processes and different frameworks like Megatron/FSDP vs. SGLang/vLLM), so explicit synchronization is required.
Note: This blog focuses exclusively on Colocated Mode, where we utilize the
update_weights_from_tensorendpoint throughout our optimization journey. In disaggregated mode, slime uses theupdate_weights_from_distributedendpoint, which transfers weights through NVLink/InfiniBand interconnects.
3. How weight sync works in slime?
In our architecture, the Megatron worker and the SGLang worker are colocated on the same physical GPUs. To achieve zero-copy tensor sharing, Megatron doesn’t send the data itself. Instead, it performs an param gathering to create a list of CUDA IPC handles. These handles are lightweight pointers to the tensors’ locations in GPU memory. SGLang then uses these handles to directly map and access the tensor data from its own process, completely eliminating memory copy overhead
Here’s the detailed 5-step workflow:
- Gather distributed tensors: Collect model weights from distributed workers across PP/TP/EP/ETP ranks in the Megatron training process. Code
- Serialize to CUDA IPC: Convert tensors into CUDA IPC handlers and aggregate them into transfer-ready buckets. Code
- API communication: Send serialized tensor data to SGLang server via the
update_weights_from_tensorendpoint. Code - Distribute to workers: Scatter CUDA IPC handlers across SGLang’s tensor parallel workers. Code
- Reconstruct and load: Deserialize CUDA IPC handlers back to tensors and load the updated weights into the inference model. Code
Why Server-Based Architecture?
- Ensuring Consistency Between Training and Inference. Since online tasks will undoubtedly use a server-based setup, using the exact same configuration for RL training can:
- Prevent discrepancies between the model’s performance during training and its metrics when deployed or evaluated in a standalone test.
- Allow full reuse of the tests and performance optimizations already made for the server with SGLang.
- Reducing the Mental Burden of Custom Rollouts.
- By using server-based engines with a router, writing rollouts becomes similar to calling a regular online service. This makes it easier for users to define custom rollout functions.
- The router’s address can be exposed externally, allowing outside agent environments to freely call the internal SGLang server. This enables a purely asynchronous training approach.
4. Our optimization journey: From 60s to 7s
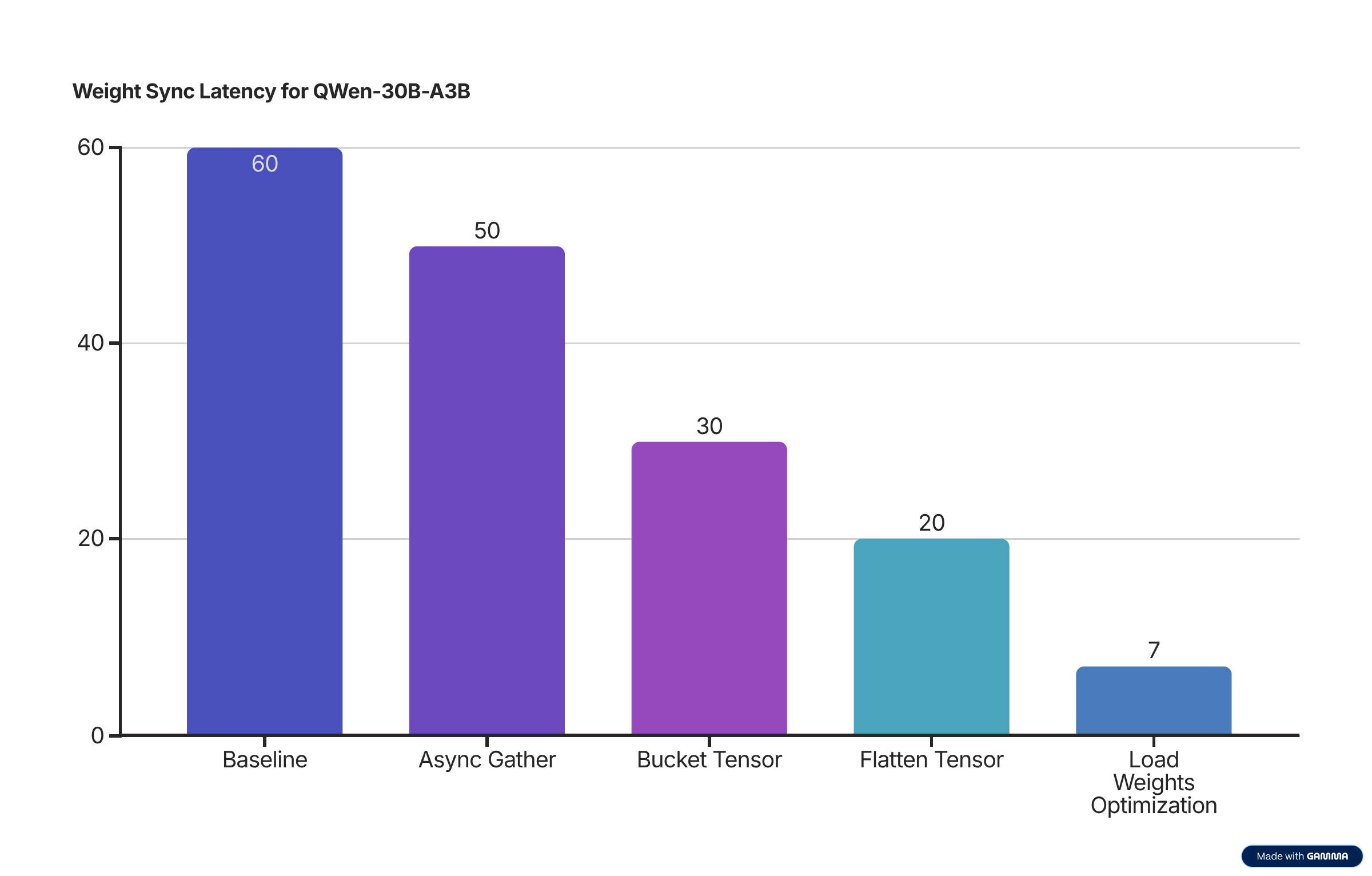
Through this optimization journey, we’ve adopted many techniques that we’ll discuss in detail below. And we will be using QWen3-30B-A3B model as an example for the following blog.
Note: The latency number was simulated according to the series of PRs3 to make it easier to understand the logic, in reality, we didn’t follow the order of improvement like the graph shown above. And reproducible setup can be found here with 8 H100 GPUs.
4.0 Cross Process Data Transfer on GPU: CUDA IPC Handler Deep Dive
When transferring large model weights between processes, we face a fundamental challenge: how to efficiently share GigaBytes of CUDA tensor data without killing performance or memory usage.
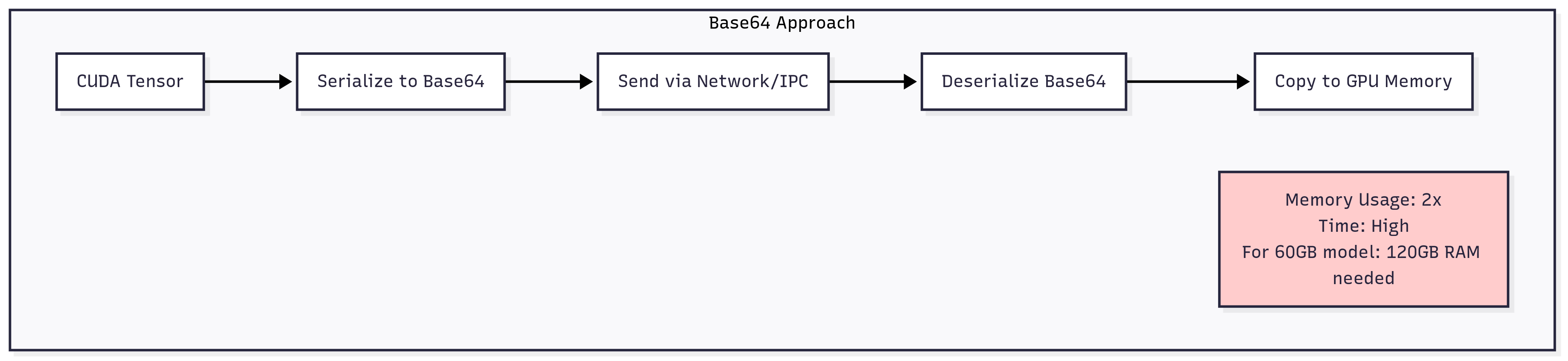
Naive Approach vs CUDA IPC
How CUDA IPC Works: The Magic Behind Zero-Copy Transfer
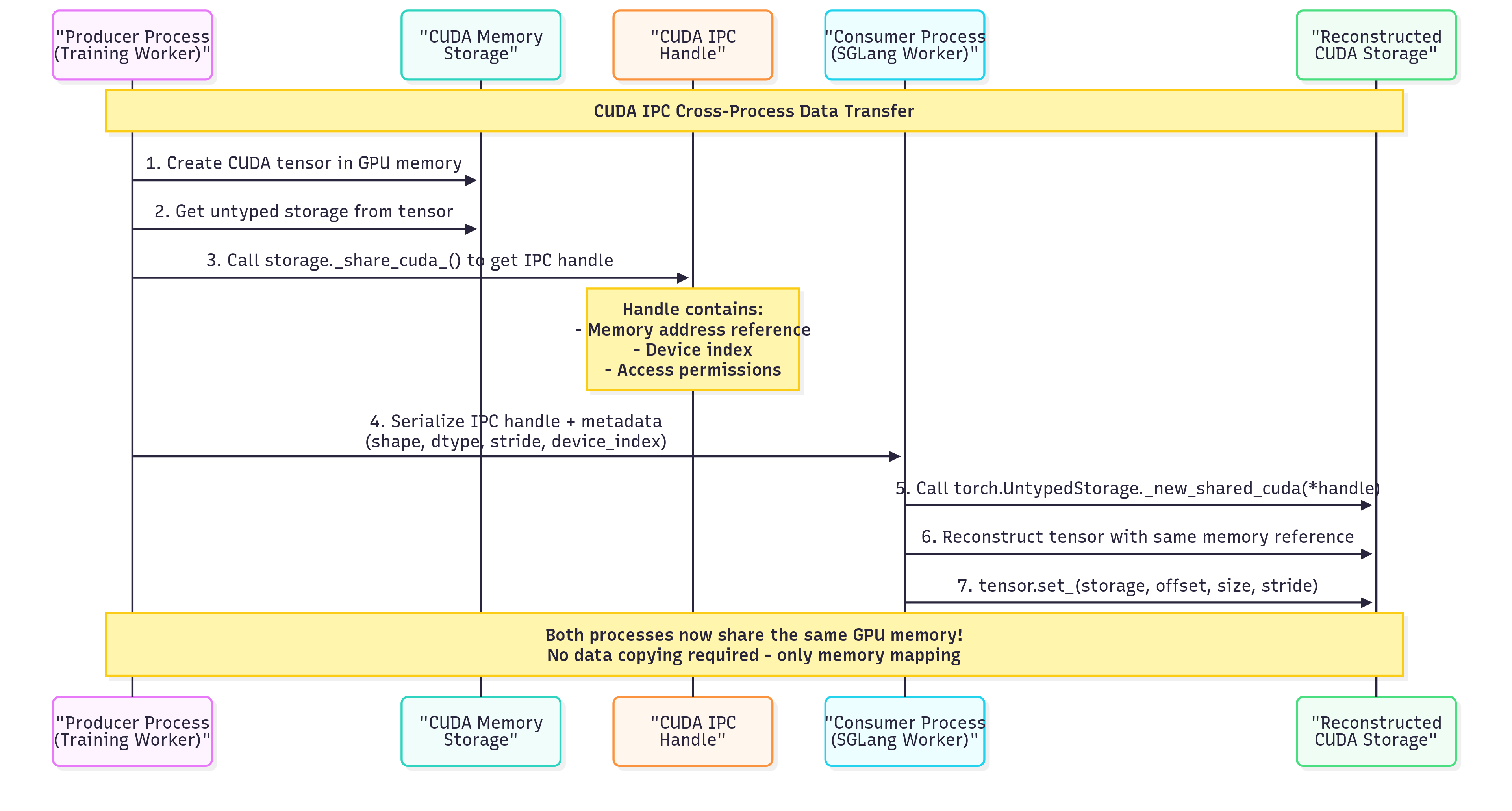
Key Advantages:
- Zero-Copy Transfer: No actual data movement - only memory mapping
- Minimal Memory Overhead: Only ~64 bytes for the IPC handle vs GBs for serialized data
- GPU-to-GPU Direct: Avoids CPU-GPU memory copies entirely
This forms our baseline implementation, achieving significant improvements over traditional serialization approaches, however, it still took us 60s to sync the weight.
4.1 Optimizing the tensor gathering process: From 60s to 50s
The first major bottleneck was in gathering tensors scattered across different distributed parallelism paradigms (Pipeline Parallel/Tensor Parallel/Expert Parallel).
Communication Strategy by Parallelism Type
| Parallelism | Communication | Reason |
|---|---|---|
| Tensor Parallel (TP) | all_gather | Each rank has partial tensor → collect all parts to reconstruct complete tensor |
| Pipeline Parallel (PP) | broadcast | Source rank has complete layer → distribute to other pipeline stages |
| Expert Parallel (EP) | broadcast | Source rank has complete expert → distribute to other expert groups |
The Solution: Async Tensor Gathering/Broadcast
In below code snippet, we use all_gather for TP Tensors as example.
def async_tensor_gathering():
# Phase 1: Start all async operations simultaneously
handles = []
for param in tensor_parallel_params:
handle = dist.all_gather(
param_partitions, param.data,
group=tp_group, async_op=True # Key: non-blocking
)
handles.append(handle)
# Phase 2: Wait for ALL operations to complete
for handle in handles:
handle.wait() # Maximize parallelism by batching waits
# Phase 3: Process all results after all communications are done
gathered_params = []
for info, direct_param, handle, param_partitions, partition_dim in gather_tasks:
param = torch.cat(param_partitions, dim=partition_dim)
gathered_params.append(param)
return gathered_params
Performance Impact:
- Before: Sequential gathering → 60s
- After: Parallel async gathering → 50s
- Improvement: 17% reduction in sync time
- Key insight: Maximize network bandwidth utilization by parallelizing communications
Code Reference: slime/backends/megatron_utils/update_weight_utils.py
Related PRs: https://github.com/THUDM/slime/pull/135
4.2 Optimizing SGLang Server Calls with Tensor Bucketing: From 50s to 30s
The next bottleneck was in the number of API calls to SGLang servers. Making individual HTTP requests for each tensor was causing significant overhead.
The Problem: Too Many Small API Calls
# Inefficient: One API call per tensor
for name, tensor in named_tensors.items():
response = requests.post(
f"http://{server_host}/update_weights_from_tensor",
json={"tensor_name": name, "tensor_data": serialize(tensor)}
)
The Solution: Tensor Bucketing
The key insight is to intelligently group parameters into optimally-sized buckets before transmission. Here’s our production implementation:
def get_param_info_buckets(args, model) -> list[list[ParamInfo]]:
param_infos = get_param_infos(args, model)
param_info_buckets = [[]]
buffer_size = 0
for info in param_infos:
# Handle different parallelism strategies
if ".experts." in info.name:
tp_size = mpu.get_expert_tensor_parallel_world_size()
else:
tp_size = mpu.get_tensor_model_parallel_world_size()
param_size = info.size * tp_size
# Create new bucket when size limit exceeded
if buffer_size + param_size > args.update_weight_buffer_size:
param_info_buckets.append([])
buffer_size = 0
param_info_buckets[-1].append(info)
buffer_size += param_size
return param_info_buckets
self.param_info_buckets = get_param_info_buckets(args, model)
# Send buckets instead of individual tensors
for param_infos in tqdm(self.param_info_buckets, disable=rank != 0, desc="Update weights"):
self._update_bucket_weights_from_tensor(param_infos)
Note: From serveral experiments, we found that 512MB is the optimal bucket size for the balance of memory and latency.
Performance Impact:
- Before: ~2000 individual API calls → 50s
- After: ~120 bucketed calls → 30s
- Improvement: 40% reduction by minimizing HTTP overhead
4.3 Tensor Flattening: Reducing CUDA IPC Overhead: From 30s to 20s
Even with tensor bucketing, we still faced a significant bottleneck: CUDA IPC handle management overhead. Each tensor required its own IPC handle creation and cleanup, leading to hundreds of expensive operations.
The Problem: Too Many CUDA IPC Operations
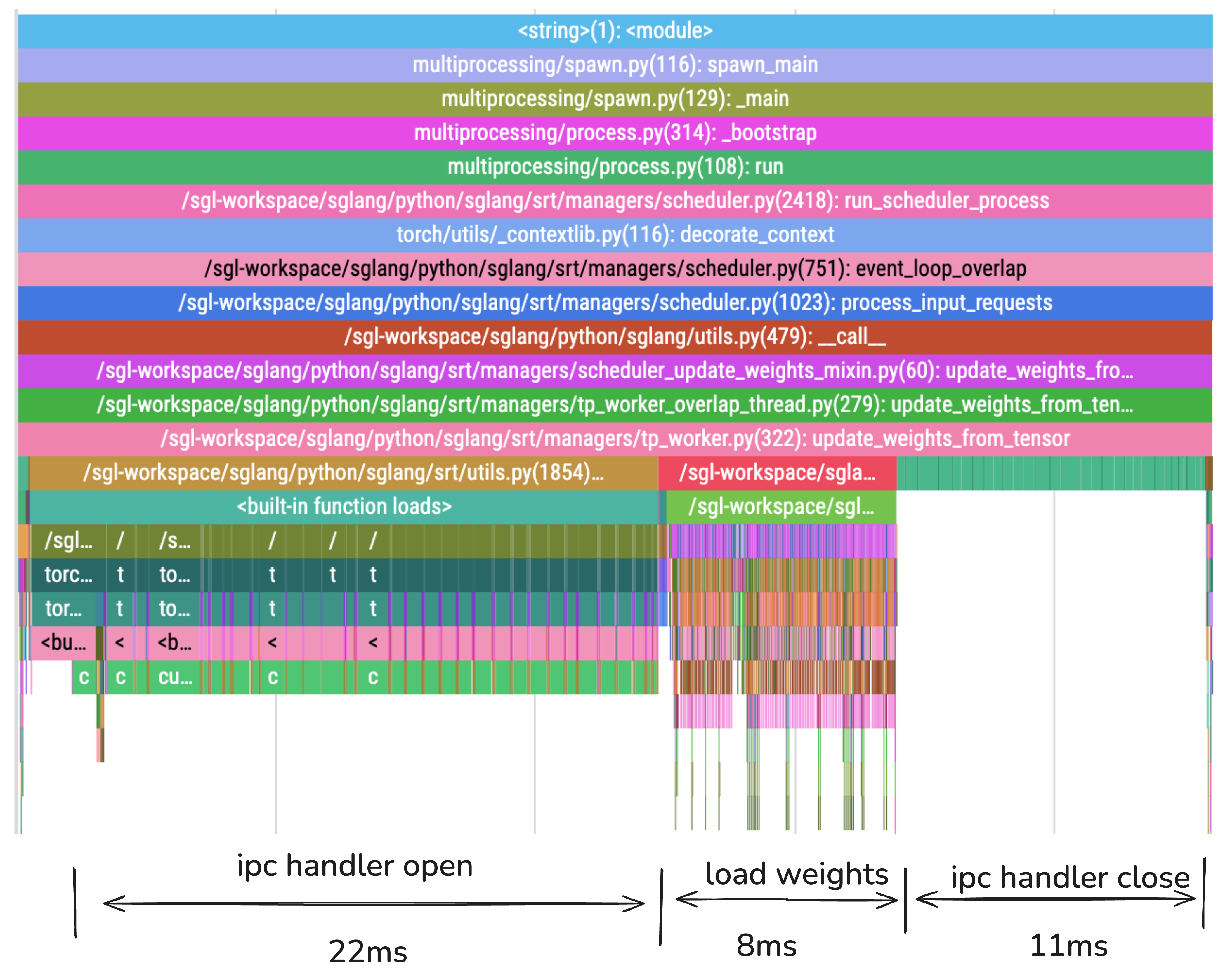
Performance Profiling Analysis
The flame graph above reveals the true bottleneck in our weight synchronization process. Here’s the breakdown:
| Phase | Duration | Percentage | Main Activities |
|---|---|---|---|
| IPC Handler Open | 22ms | 54% | CUDA IPC handle creation and memory mapping |
| Load Weights | 8ms | 19% | Actual weight loading and tensor reconstruction |
| IPC Handler Close | 11ms | 27% | CUDA IPC cleanup and resource deallocation |
| Total | 41ms | 100% | Complete weight update cycle in SGLang |
Critical Finding: 81% of the time is spent on CUDA IPC operations (open + close), while only 19% is used for actual weight loading. This explains why tensor flattening provides such dramatic improvements.
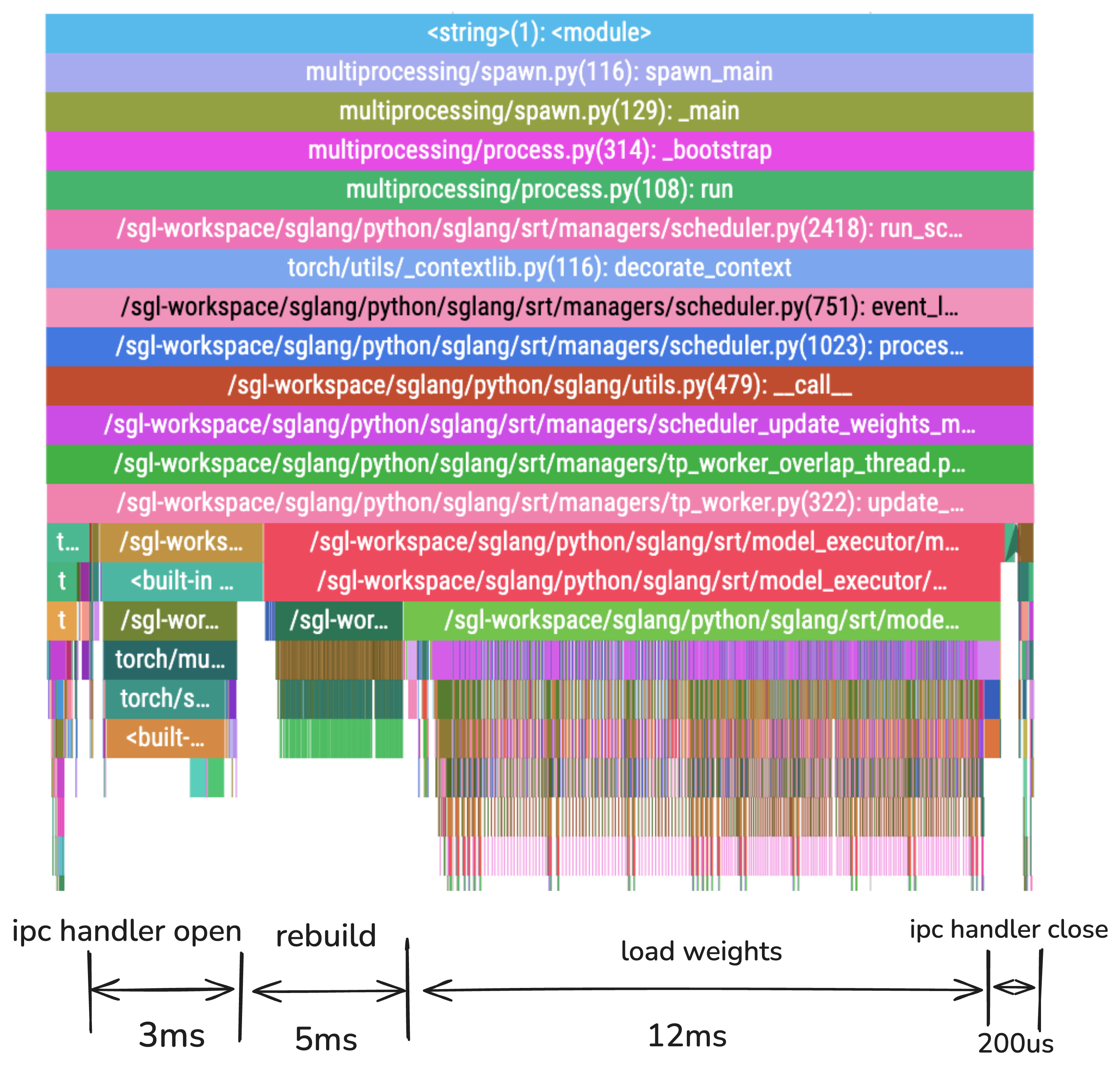
Performance After Tensor Flattening
| Phase | Duration | Percentage | Improvement |
|---|---|---|---|
| IPC Handler Open | 3ms | 15% | 86% faster |
| Rebuild | 5ms | 25% | New phase for tensor reconstruction |
| Load Weights | 12ms | 60% | Small Variance |
| IPC Handler Close | 200μs | 1% | 98% faster |
| Total | 20ms | 100% | 51% improvement vs 41ms without flattening |
Key Achievement: By flattening tensors, we reduced IPC operations from 81% to 16% of total time, while weight loading became the dominant phase at 60% - exactly what we want!
For technical details such as how to implement the tensor flattening, please refer to the following PRs:
Related PRs:
4.4 Load Weight Optimization: Final Performance Gains: From 20s to 7s
After optimizing the IPC overhead, we identified additional bottlenecks in the weight loading process itself, particularly for MoE models.
Key Optimizations:
1. Parameter Dictionary Caching
# Before: Expensive model traversal on every weight update
params_dict = dict(self.named_parameters())
# After: Cache the parameter dictionary
if not hasattr(self, "_cached_params_dict"):
self._cached_params_dict = dict(self.named_parameters())
params_dict = self._cached_params_dict
2. Expert Map GPU Migration Optimization
# Avoid repeated GPU-to-CPU synchronization for expert mapping
if self.expert_map_cpu is not None and self.expert_map_gpu is None:
# Move expert map to GPU once and cache it
self.expert_map_gpu = self.expert_map_cpu.to(device="cuda")
3. CUDA Device Caching
# Cache CUDA device queries to avoid repeated expensive calls
@lru_cache(maxsize=8)
def get_device(device_id: Optional[int] = None) -> str:
# Cached device lookup eliminates repeated torch.cuda.is_available() calls
Performance Impact:
- Before: Various weight loading bottlenecks → 20s
- After: Optimized parameter caching and device handling → 7s
- Improvement: 65% reduction in final weight loading time
Key Insights:
- Most performance optimizations in SGLang focus on the forward pass, while weight loading optimization receives less attention. This creates abundant low-hanging fruit opportunities, as demonstrated by the PRs above.
Related PRs:
5. Future Optimizations
Several exciting optimization opportunities remain:
- Overlap Communication: Pipeline gathering and sending operations
- Async Weight Loading: Non-blocking model weight updates
- Zero-Redundancy Layout: Pre-calculate inference engine memory layout and do zero-redundancy copy
6. Acknowledgments
We extend our gratitude to:
- The slime Team for the light and power RL training framework
- The SGLang Team for the high-performance inference engine and foundation work of weights sync.