Implement Flash Attention Backend in SGLang - Basics and KV Cache
Notes on SGLang attention backend internals, from Flash Attention basics to KV cache layout and execution flow.

Authored by
Biao He

Qingquan Song
0x0. Introduction
In the past few weeks, we’ve implemented the Flash Attention Backend end-to-end in SGLang, which is now the default attention backend as of SGLang 0.4.6 release.
 Throughout this journey, we learned a lot about how Attention Backend functions in modern LLM serving engines and developed a deeper understanding of Flash Attention itself.
Throughout this journey, we learned a lot about how Attention Backend functions in modern LLM serving engines and developed a deeper understanding of Flash Attention itself.
In this series, we’ll walk through the implementation details, sharing insights that we hope will benefit anyone looking to implement their own attention backend in LLM serving engines.
Table of Contents for the series
This series will be split into 3 parts:
- Part 1: Basics, KV Cache and CUDA Graph Support (this post)
- Part 2: Speculative Decoding Support (work is done, blog is coming soon)
- Part 3: MLA, Llama 4, Sliding Window and Multimodal Support (work is done, blog is coming soon)
Latest Status of Attention Backend in SGLang
| Backend | Page Size > 1 | Spec Decoding | MLA | Llama 4 | MultiModal | FP8 |
|---|---|---|---|---|---|---|
| FlashAttention | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| FlashInfer | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Triton | ❌ | ✅ | ✅ | ❌ | ❌ | ✅ |
| Torch | ❌ | ❌ | ❌ | ❌ | ❌ | ❌ |
Benchmark Results
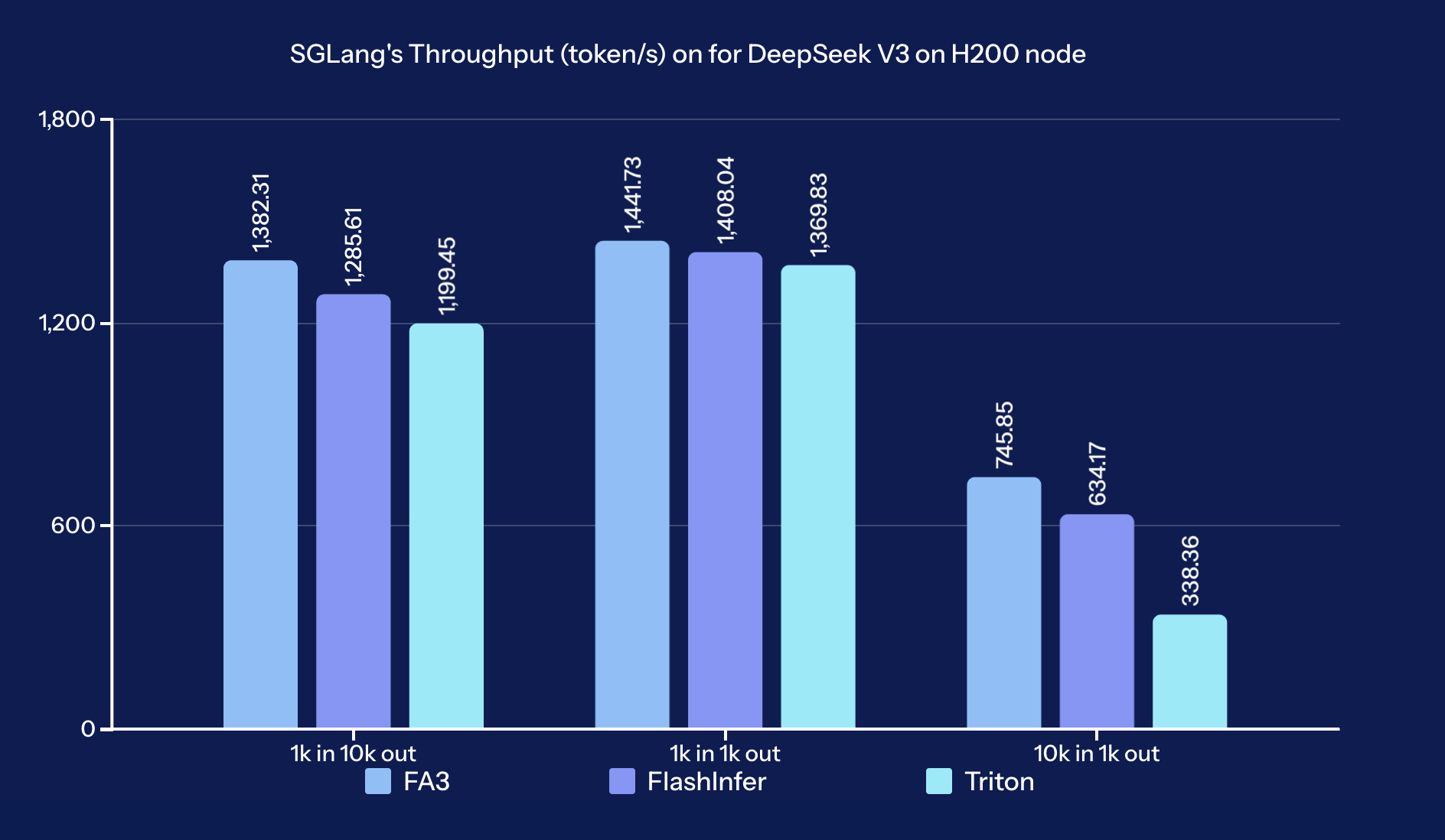
The benchmark results demonstrate that FA3 consistently delivers the highest throughput across all tested scenarios, outperforming both FlashInfer and Triton, especially as the input or output size increases.
We followed the same benchmark setup as this comment being used. Detailed benchmark results are available in this sheet
0x1. Background and Motivation
What is Flash Attention?
Flash Attention1 is an IO-aware exact attention algorithm that uses tiling to reduce the number of memory reads/writes between GPU high bandwidth memory (HBM) and GPU on-chip SRAM.
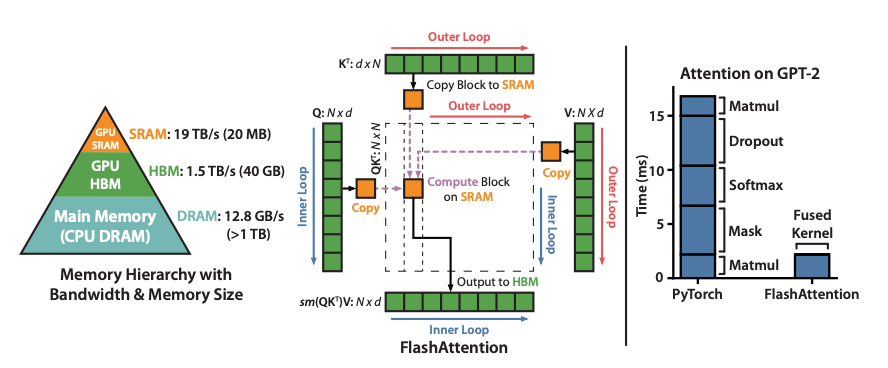 It has been widely used in LLM inference and training, and is the default attention backend in modern serving engines like SGLang, vLLM, etc.
It has been widely used in LLM inference and training, and is the default attention backend in modern serving engines like SGLang, vLLM, etc.
In most cases, it’s fine to treat it as a black box. However, by understanding its core logic, we can use it more intelligently.
I highly recommend this article2 to understand the core logic of Flash Attention.
How Attention Backend works in SGLang
SGLang Architecture

SGLang, as a modern LLM Serving Engine, has three major components (in logical view)3:
- Server Components: Responsible for handling the incoming requests and sending responses.
- Scheduler Components: Responsible for construct batches and send to Worker.
- Model Components: Responsible for the model inference.
Let’s focus on the model forward pass in the diagram above.
In step 8: the ModelRunner processes the ForwardBatch and calls model.forward to execute the model’s forward pass.
In step 9: model.forward will call each layer’s forward function, and the majority of the time is spent on the self-attention part. Hence the attention backend becomes the bottleneck of the model inference. In addition to performance, there are many different kinds of attention variants such as MHA, MLA, GQA, Sliding Window, Local Attention which require carefully optimized attention backend implementations.
Attention Backend Inheritance
Here is the inheritance relationship of the attention variants: 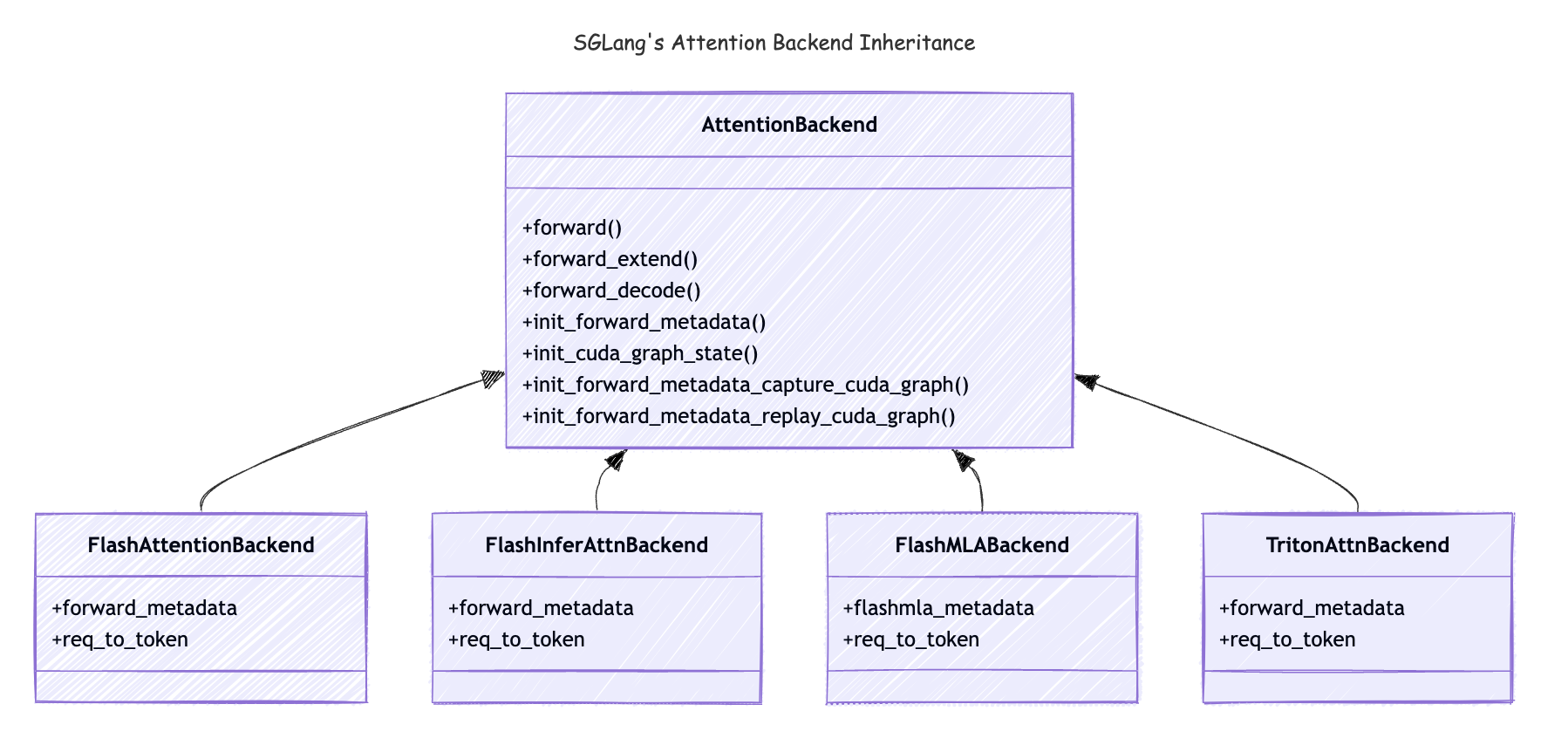
Let’s walk through the method in the AttentionBackend class to see what’s the backbone of the attention backend in SGLang.
-
forward(): Whenmodel.forward()is called, theforwardmethod in theAttentionBackendwill be called. It will be callingforward_extend()andforward_decodeaccording to theforward_batch.forward_mode. In this blog, we only focus onEXTENDandDECODEmode. -
forward_extend(): This method will be called for each layer when theforward_modeisEXTEND. -
forward_decode(): This method will be called for each layer when theforward_modeisDECODE. -
init_cuda_graph_state(): This method will be called during the server startup, it will preallocate those tensors which will be used in the CUDA Graph replay. -
init_forward_metadata(): This method will be called when themodel.forward()is called. It could precalculate some metadata for the entiremodel.forward()call, reused by each layer, this is critical for accelerating the model inference. What’s ironic is, this metadata is the most complicated part of the attention backend, once we set it up, the call of \(\text{softmax}\left({\mathbf{Q}\mathbf{K}^\top}\right)\mathbf{V}\) computation is quite straightforward in this context. -
init_forward_metadata_capture_cuda_graph: This method will be called during the server startup,CUDAGraphRunnerwill call this method during CUDA Graph Capture. CUDA Graph will stored in memory withinCUDAGraphRunner’sself.graphsobject. -
init_forward_metadata_replay_cuda_graph: This method will be called during each layer’sforward_decodebeing called. It will setup the metadata for theforwade_decodecall to make sure the CUDA Graph replay could be done correctly.
By far, we have covered all of the methods we need to implement for the attention backend. We will discuss it in following sections.
How KV Cache works in SGLang
You might be curious about why there is a req_to_token in each Attention Backend class. And I didn’t put it there accidentally. Actually, KV Cache, as the backbone of all LLM Serving Engines, is also very critical to Attention Backend, so let’s briefly take a look at it.
There are two-level memory pools to manage KV cache4. 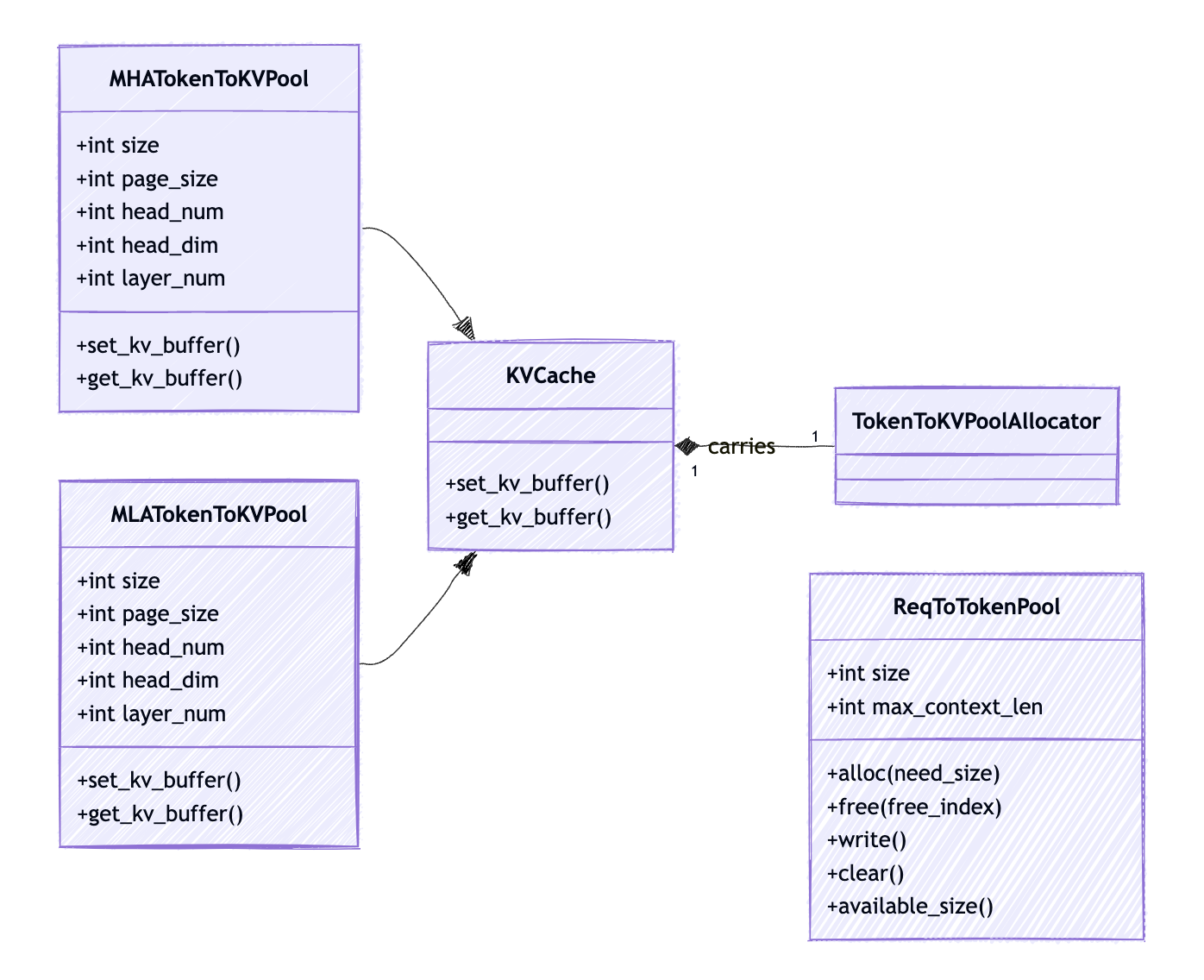
req_to_token_pool
A map from a request to its tokens’ KV cache indices. And this is the req_to_token we mentioned in Attention Backend Diagram.
- Shape: Max Allowed Requests Number (being set by argument
max-running-requestsfor the maximum number of requests to run concurrently) * Max Context Length for each request (being set by configmodel_config.context_len) - Access:
- Dim0:
req_pool_indicesidentify the specific request - Dim1: token positions in req (starting from 0, 1, 2…), identify the specific token in the request
- Value:
out_cache_locfor token, it points to the KV cache indices associated with the token identified by Dim0 and Dim1
- Dim0:
token_to_kv_pool
req_to_token_pool maintained the map between request to tokens KV cache indices, token_to_kv_pool further maps token from its KV cache indices to its real KV cache data. Note that, for different attention implementation, like MHA, MLA, Double Sparsity, token_to_kv_pool could have different implementation.
- Layout: Number of Layers * Max Allowed Tokens Number * Number of Head * Head Dimension
- Access:
- Dim0:
layer_ididentify the specific layer - Dim1:
out_cache_locidentify the specific KV cache indices (free slots) - Dim2: Head
- Dim3: Head Dimension
- Value:
cache_kfor k_buffer andcache_vfor v_buffer, the real KV Cache Data
Note that we normally retrieve the KV Cache for entire layer all together, because we would need all prior tokens’ KV in a request to do forward.
- Dim0:
In attention backend, we only need to know what req_to_token_pool is and the rest of KV Cache management is transparent to the attention backend.
Let’s give an intuitive example of what req_to_token_pool looks like:
- Assume we have 2 requests, and each request has 7 tokens.
- Then
req_to_token_poolis a tensor with shape (2, 7), where each entry maps a token in a request to its corresponding KV cache index.req_to_token_pool = [ [1, 2, 3, 4, 5, 6, 7], [8, 9, 10, 11, 12, 13, 14] ]seq_lensis [7, 7]. - After one forward_extend that adds a new token to each request, the
req_to_token_poolwill be updated to:req_to_token_pool = [ [1, 2, 3, 4, 5, 6, 7, 15], [8, 9, 10, 11, 12, 13, 14, 16] ]seq_lensis [8, 8]. - If the first request is complete and we run another decode for the second request, the
req_to_token_poolwill be updated to:req_to_token_pool = [ [1, 2, 3, 4, 5, 6, 7, 15], [8, 9, 10, 11, 12, 13, 14, 16, 17] ]seq_lensis [8, 9].
With the above knowledge about KV Cache structure, we now have the foundation to implement our FlashAttention backend. The next step is to identify the correct parameters for the flash_attn_with_kvcache API to create a minimal working implementation.
For more details on KV Cache, refer to the Awesome-ML-SYS-Tutorial: KV Cache Code Walkthrough.
0x2. FlashAttention3 Backend Basic Implementation
OK, let’s start diving into the implementation of the FlashAttention backend in SGLang.
Here is the PR for the basic implementation: sgl-project/sglang#4680. I simplified the code in this blog for brevity and only focus on the core logic.
Tri Dao’s FlashAttention 3 Kernel API
Tri Dao has provided several public APIs for Flash Attention 3, the entry point is hopper/flash_attn_interface.py.
We opted for flash_attn_with_kvcache for two key reasons: it eliminates the overhead of manually assembling key-value pairs by accepting the entire page table directly, and it provides native support for Paged KV Cache (Page Size > 1), which is not available in flash_attn_varlen_func.
Let’s take a quick look at the flash_attn_with_kvcache API:
# we omiited some arguments for brevity
def flash_attn_with_kvcache(
q,
k_cache,
v_cache,
cache_seqlens: Optional[Union[(int, torch.Tensor)]] = None,
page_table: Optional[torch.Tensor] = None,
cu_seqlens_q: Optional[torch.Tensor] = None,
cu_seqlens_k_new: Optional[torch.Tensor] = None,
max_seqlen_q: Optional[int] = None,
causal=False,
):
"""
Arguments:
q: (batch_size, seqlen, nheads, headdim)
k_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim) if there's no page_table,
or (num_blocks, page_block_size, nheads_k, headdim) if there's a page_table (i.e. paged KV cache)
page_block_size must be a multiple of 256.
v_cache: (batch_size_cache, seqlen_cache, nheads_k, headdim_v) if there's no page_table,
or (num_blocks, page_block_size, nheads_k, headdim_v) if there's a page_table (i.e. paged KV cache)
cache_seqlens: int, or (batch_size,), dtype torch.int32. The sequence lengths of the
KV cache.
page_table [optional]: (batch_size, max_num_blocks_per_seq), dtype torch.int32.
The page table for the KV cache. It will derived attention backend's req_to_token_pool.
cu_seqlens_q: (batch_size,), dtype torch.int32. The cumulative sequence lengths of the query.
cu_seqlens_k_new: (batch_size,), dtype torch.int32. The cumulative sequence lengths of the new key/value.
max_seqlen_q: int. The maximum sequence length of the query.
causal: bool. Whether to apply causal attention mask (e.g., for auto-regressive modeling).
Return:
out: (batch_size, seqlen, nheads, headdim).
"""
Initialization
With above information, now the mission is much clear, we just need to figure out those parameters for flash_attn_with_kvcache API, and we can achieve the bare minimum of FlashAttention backend.
Let’s start from the initialization of the FlashAttentionBackend class and FlashAttentionMetadata class.
@dataclass
class FlashAttentionMetadata:
"""Metadata which will be created once during model forward and reused across layers forward."""
cache_seqlens_int32: torch.Tensor = None # Sequence Lengths in int32
max_seq_len_q: int = 0 # Max Sequence Length for Query
max_seq_len_k: int = 0 # Max Sequence Length for Key
cu_seqlens_q: torch.Tensor = None # Cumulative Sequence Lengths for Query
cu_seqlens_k: torch.Tensor = None # Cumulative Sequence Lengths for Key
page_table: torch.Tensor = None # Page Table indicate the KV Indices for each sequence
class FlashAttentionBackend(AttentionBackend):
"""FlashAttention backend implementation."""
def __init__(
self,
model_runner: ModelRunner,
):
super().__init__()
self.forward_metadata: FlashAttentionMetadata = None # metadata for the forward pass
self.max_context_len = model_runner.model_config.context_len # max context length set by model config
self.device = model_runner.device # device of the model (GPU)
self.decode_cuda_graph_metadata = {} # metadata for accelerating decode process
self.req_to_token = model_runner.req_to_token_pool.req_to_token # map from a request to its tokens' KV cache indices
Init Forward Metadata
def init_forward_metadata(self, forward_batch: ForwardBatch):
"""Initialize forward metadata during model forward and reused across layers forward
Args:
forward_batch: `ForwardBatch` object, contains the forward batch information like forward_mode, batch_size, req_pool_indices, seq_lens, out_cache_loc
"""
# Initialize metadata
metadata = FlashAttentionMetadata()
# Get batch size
batch_size = forward_batch.batch_size
# Get original sequence lengths in batch
seqlens_in_batch = forward_batch.seq_lens
# Get device of the model, e.g: cuda
device = seqlens_in_batch.device
# Get sequence lengths in int32
metadata.cache_seqlens_int32 = seqlens_in_batch.to(torch.int32)
# Get max sequence length for key
# Note that we use seq_lens_cpu to skip a device sync
# See PR: https://github.com/sgl-project/sglang/pull/4745
metadata.max_seq_len_k = forward_batch.seq_lens_cpu.max().item()
# Get cumulative sequence lengths for key
metadata.cu_seqlens_k = torch.nn.functional.pad(
torch.cumsum(seqlens_in_batch, dim=0, dtype=torch.int32), (1, 0)
)
# Get page table, we cutoff by the max sequence length
metadata.page_table = forward_batch.req_to_token_pool.req_to_token[
forward_batch.req_pool_indices, : metadata.max_seq_len_k
]
if forward_batch.forward_mode == ForwardMode.EXTEND:
# Get sequence lengths in int32
metadata.max_seq_len_q = max(forward_batch.extend_seq_lens_cpu)
metadata.cu_seqlens_q = torch.nn.functional.pad(
torch.cumsum(forward_batch.extend_seq_lens, dim=0, dtype=torch.int32), (1, 0)
)
elif forward_batch.forward_mode == ForwardMode.DECODE:
# For decoding, query length is always 1
metadata.max_seq_len_q = 1
# Get cumulative sequence lengths for query
metadata.cu_seqlens_q = torch.arange(
0, batch_size + 1, dtype=torch.int32, device=device
)
# Save metadata, hence forward_extend and forward_decode could reuse it
self.forward_metadata = metadata
Forward Extend and Forward Decode
In model forward, model_runner will call init_forward_metadata to initialize the metadata for the attention backend and then call the actual forward_extend and forward_decode. Hence the implementation of forward_extend and forward_decode is straightforward.
def forward_extend(
self,
q: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
layer: RadixAttention,
forward_batch: ForwardBatch,
save_kv_cache=True,
):
# Get the KV Cache location from the forward batch
cache_loc = forward_batch.out_cache_loc
# Save the KV Cache for the new tokens
if save_kv_cache:
forward_batch.token_to_kv_pool.set_kv_buffer(layer, cache_loc, k, v)
# Use precomputed metadata
metadata = self.forward_metadata
# Get the KV Cache for the previous tokens
key_cache, value_cache = forward_batch.token_to_kv_pool.get_kv_buffer(layer.layer_id)
o = flash_attn_with_kvcache(
q=q.contiguous().view(-1, layer.tp_q_head_num, layer.head_dim),
k_cache=key_cache.unsqueeze(1),
v_cache=value_cache.unsqueeze(1),
page_table=metadata.page_table,
cache_seqlens=metadata.cache_seqlens_int32,
cu_seqlens_q=metadata.cu_seqlens_q,
cu_seqlens_k_new=metadata.cu_seqlens_k,
max_seqlen_q=metadata.max_seq_len_q,
causal=True, # for auto-regressive attention
)
# forward_decode is identical to forward_extend, we've set the metadata differently in init_forward_metadata already
Until now, a bare minimum FlashAttention backend is implemented. We could use this backend to do the attention forward pass.
0x3. CUDA Graph Support
What is CUDA Graph?
CUDA Graph is a feature in NVIDIA’s CUDA platform that allows you to capture a sequence of GPU operations and replay them as a single, optimized unit. Traditionally, each GPU kernel launch from the CPU incurs some launch latency, and the CPU must coordinate each step in sequence. This overhead can become significant, especially for workloads with many small kernels.5
With CUDA Graph, you can record a series of operations (such as A, B, C, D, E in the diagram) into a graph, and then launch the entire graph in one go. This approach eliminates repeated CPU launch overhead and enables the GPU to execute the operations more efficiently, resulting in significant time savings. The diagram below illustrates this concept: The top part shows the traditional approach, where each kernel launch incurs CPU overhead. The bottom part shows the CUDA Graph approach, where the entire sequence is launched as a single graph, reducing CPU time and improving overall throughput.
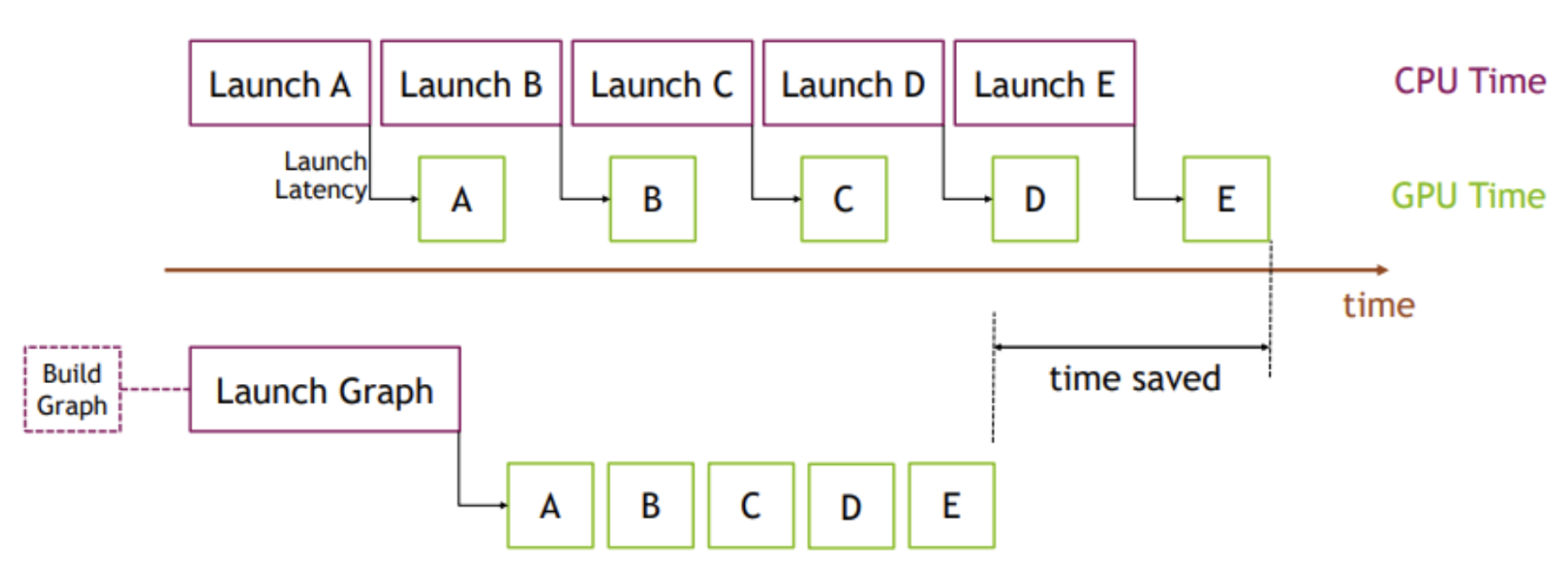
Actually, I found that a lot of significant speedups in modern LLM Serving Engine comes from parallelizing multiple workloads and overlapping their execution. I can easily name a few examples:
- CUTLASS’s overlap of TMA and WGMMA6
- Flash Attention’s overlap of GEMM and Softmax7
- SGLang’s Zero-Overhead Batch Scheduler8
I believe there are more opportunities with this simple but effective philosophy, it make me really excited to see more and more cool projects being built on top of next generation hardwares.
How CUDA Graph works in SGLang
In SGLang, CUDA Graph’s capture and replay was done by CUDAGraphRunner class. Given that the framework already has a pretty decent design about how CUDAGraphRunner works with attention backend, we can focus on implementing those three methods:
init_cuda_graph_state()init_forward_metadata_capture_cuda_graph()init_forward_metadata_replay_cuda_graph()
You can find the detailed flow of how CUDAGraphRunner works with attention backend in the diagram below:
Init CUDA Graph State
def init_cuda_graph_state(self, max_bs: int):
"""Initialize CUDA graph state for the attention backend.
Args:
max_bs (int): Maximum batch size to support in CUDA graphs
This creates fixed-size tensors during server startup that will be reused during CUDA graph replay to avoid memory allocations.
"""
self.decode_cuda_graph_metadata = {
# Sequence Lengths in int32 (batch_size)
"cache_seqlens": torch.zeros(max_bs, dtype=torch.int32, device=self.device),
# Cumulative Sequence Lengths for Query (batch_size + 1)
"cu_seqlens_q": torch.arange(
0, max_bs + 1, dtype=torch.int32, device=self.device
),
# Cumulative Sequence Lengths for Key (batch_size + 1)
"cu_seqlens_k": torch.zeros(
max_bs + 1, dtype=torch.int32, device=self.device
),
# Page Table for token mapping from request to tokens' KV cache indices (batch_size, max_context_len)
"page_table": torch.zeros(
max_bs,
self.max_context_len,
dtype=torch.int32,
device=self.device,
),
}
It’s worth noting that, we found for metadata with tensor type, we need to be initialized first and then copy the value into the preallocated tensors, otherwise CUDA Graph will not work. For those metadata with scalar type (e.g:
max_seq_len_q,max_seq_len_k), we can directly create new variable.
Prepare Metadata for Capture
def init_forward_metadata_capture_cuda_graph(
self,
bs: int,
num_tokens: int,
req_pool_indices: torch.Tensor,
seq_lens: torch.Tensor,
encoder_lens: Optional[torch.Tensor],
forward_mode: ForwardMode,
):
"""Initialize forward metadata for capturing CUDA graph."""
metadata = FlashAttentionMetadata()
device = seq_lens.device
batch_size = len(seq_lens)
metadata.cache_seqlens_int32 = seq_lens.to(torch.int32)
if forward_mode == ForwardMode.DECODE:
metadata.cu_seqlens_q = torch.arange(
0, batch_size + 1, dtype=torch.int32, device=device
)
metadata.max_seq_len_k = seq_lens.max().item()
metadata.cu_seqlens_k = torch.nn.functional.pad(
torch.cumsum(seq_lens, dim=0, dtype=torch.int32), (1, 0)
)
metadata.page_table = self.decode_cuda_graph_metadata["page_table"][
req_pool_indices, :
]
else:
raise NotImplementedError(f"Forward mode {forward_mode} is not supported yet")
self.decode_cuda_graph_metadata[bs] = metadata
To be honest, we don’t care too much about the actual value being set in
init_forward_metadata_capture_cuda_graphbecause we will override ininit_forward_metadata_replay_cuda_graphanyway. We just need to make sure the tensor shape is correct.
Prepare Metadata for Replay
def init_forward_metadata_replay_cuda_graph(
self,
bs: int,
req_pool_indices: torch.Tensor,
seq_lens: torch.Tensor,
seq_lens_sum: int,
encoder_lens: Optional[torch.Tensor],
forward_mode: ForwardMode,
seq_lens_cpu: Optional[torch.Tensor],
out_cache_loc: torch.Tensor = None,
):
"""Initialize forward metadata for replaying CUDA graph."""
# Get the sequence lengths in batch, we slice it out from the preallocated tensors
seq_lens = seq_lens[:bs]
# Get the sequence lengths in CPU, we slice it out from the preallocated tensors
seq_lens_cpu = seq_lens_cpu[:bs]
# Get the request pool indices, we slice it out from the preallocated tensors
req_pool_indices = req_pool_indices[:bs]
# Get the device of the model
device = seq_lens.device
# Get the metadata for the decode, which have been precomputed in init_forward_metadata_capture_cuda_graph() and initialized in init_cuda_graph_state()
metadata = self.decode_cuda_graph_metadata[bs]
if forward_mode == ForwardMode.DECODE:
# Update the sequence lengths with actual values
metadata.cache_seqlens_int32 = seq_lens.to(torch.int32)
# Update the maximum sequence length for key with actual values
metadata.max_seq_len_k = seq_lens_cpu.max().item()
# Update the cumulative sequence lengths for key with actual values
metadata.cu_seqlens_k.copy_(
torch.nn.functional.pad(
torch.cumsum(seq_lens, dim=0, dtype=torch.int32), (1, 0)
)
)
# Update the page table with actual values
metadata.page_table[:, : metadata.max_seq_len_k].copy_(
self.req_to_token[req_pool_indices[:bs], : metadata.max_seq_len_k]
)
else:
raise NotImplementedError(f"Forward mode {forward_mode} is not supported yet")
self.forward_metadata = metadata
Until now, a CUDA Graph supported FlashAttention backend is implemented!
0x4. Conclusion
In this article, we’ve explored several key components:
- The fundamentals of FlashAttention and its operational principles
- The architecture of Attention Backend in SGLang
- The implementation details of KV Cache in SGLang
- A step-by-step approach to implementing a basic FlashAttention backend
- The process of integrating CUDA Graph support for optimized performance
In our upcoming articles, we’ll delve into more advanced topics including Speculative Decoding (a challenging implementation that took us over 3 weeks!), as well as MLA, Llama 4, Multimodal capabilities, and more!
0x5. Thoughts about Open Source
This is my first significant contribution to a popular open source project, and I’m truly grateful for the community’s support and the maintainers’ guidance throughout this process.
For MLSys enthusiasts who want to begin their own journey in open source, I highly recommend joining the SGLang community. Here are some personal tips from my experience:
- You don’t need to be an expert to start contributing. Contributions to documentation, benchmarking, and bug fixes are all valuable and welcomed. In fact, my first two PRs were focused on documentation and benchmarking.
- Finding a good first issue can be challenging in established projects like SGLang. My approach was to follow a specific area closely (e.g: Quantization), monitor relevant PRs and issues, and offer assistance with smaller tasks by reaching out to PR authors through comments or Slack.
- Be accountable for your contributions and commitments. In open source communities, professional relationships are built on trust and reliability. Remember that most contributors are balancing open source work with full-time jobs, so respecting everyone’s time and effort is essential.