Efficient RL Training - Optimizing Memory Usage in verl
A systems deep dive into memory pressure in RL training and the techniques that make larger policy rollouts feasible.

Authored by
Biao He

Ata Fatahi
1. Introduction
Reinforcement learning (RL) for large language models (LLMs) presents unique challenges due to its integration of inference and training in each step, demanding significant scalability and resource efficiency. The verl library, designed for RL training of LLMs, combines advanced training strategies like Fully Sharded Data Parallel (FSDP) and Megatron-LM with inference engines such as SGLang for efficient rollout generation. This blog post details the SGLang RL team’s efforts to optimize memory usage in verl, focusing on techniques that reduce peak memory demands and enable training larger models on limited GPU resources.
2. High-Level RL Training Workflow
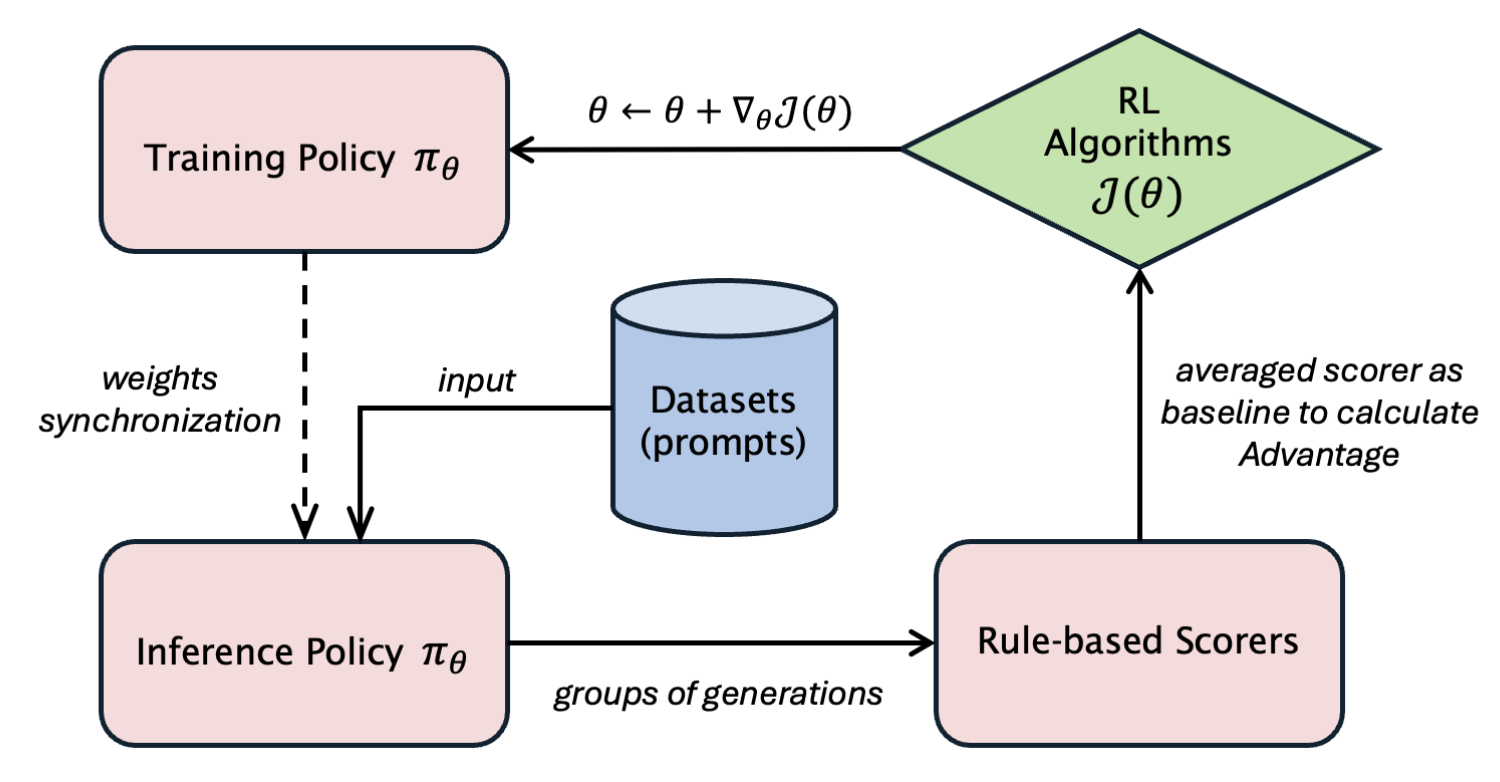
The diagram above illustrates the online RL training proces, simplified by omitting the reference and critic models and assuming a basic reward function (common in code and reasoning tasks) instead of a reward model. The policy model exists in two instances: one optimized for training (using FSDP or Megatron-LM) and another for inference (using SGLang or vLLM).1
Simplified PPO Example
Below is a simplified implementation using Proximal Policy Optimization (PPO):
for prompts, pretrain_batch in dataloader:
# Stage 1: Rollout generation (inference)
batch = actor.generate_sequences(prompts)
# Stage 2: Prepare experience
batch = reference.compute_log_prob(batch)
batch = reward.compute_reward(batch) # Reward function or model
batch = compute_advantages(batch, algo_type)
# Stage 3: Actor training
actor_metrics = actor.update_actor(batch)
Each iteration involves a rollout (inference) phase using the actor model, followed by training. verl’s design co-locates both the rollout and training versions of the actor model on the same GPUs, optimizing resource sharing but complicating memory management. This post focuses on addressing the actor model’s memory challenges.
3. The Memory Challenge
RL training in verl requires seamless transitions between rollout and training phases, both of which are memory-intensive. Co-locating these phases on the same GPUs risks out-of-memory (OOM) errors, especially with large models. Below is the memory breakdown for Qwen2.5-7B-Instruct on an H200 GPU node (8 GPUs, ~141 GB VRAM each) using FSDP for training and SGLang for rollout.
Training Phase Memory Breakdown
With FSDP sharding across 8 GPUs, and enable FULLY SHARDED mode with Full Activation Checkpointing, each GPU holds:
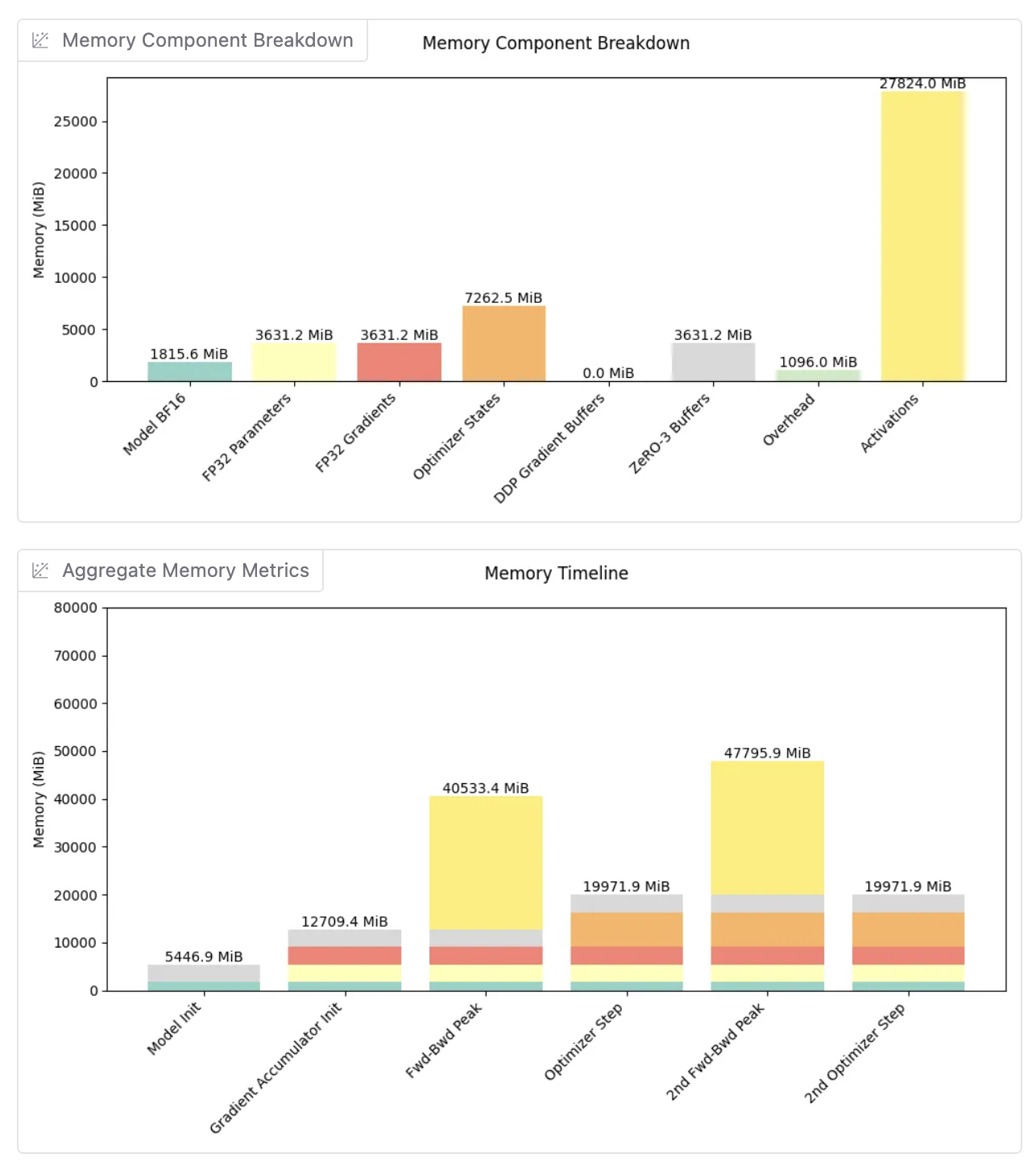
Peak Training Memory: ~48 GB per GPU
Rollout Phase Memory Breakdown
During inference, the full model is typically loaded (not sharded):
- Model Weights: ~15.4 GB (full model for inference efficiency)
- KV Cache: ~60-90 GB (dominant factor, can be tuned by
mem-fractionin SGLang, assuming0.7-0.9ratio) - CUDA Graph: ~1-3 GB (captures computation graph for inference acceleration)
- Input/Output Buffers: ~3-7 GB (request batching and response generation)
Total Rollout Memory: ~80-115 GB per GPU
Managing these memory demands on the same GPUs requires careful optimization to avoid OOM errors during phase transitions.
4. Memory Optimization Journey
4.1: The Naive Approach
In our initial approach, we kept both training model weights and the inference engine (SGLang) in GPU memory without offloading.
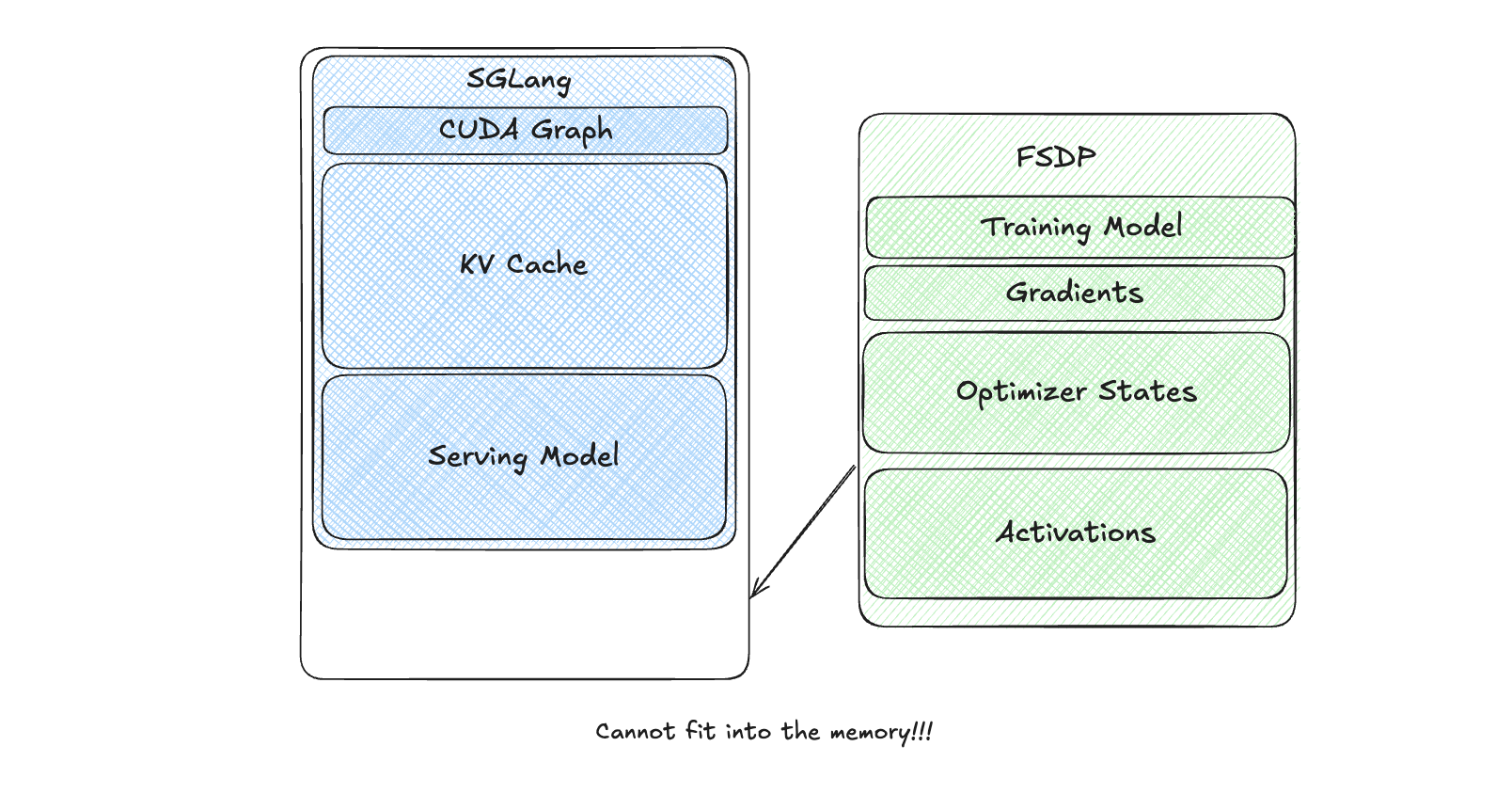
However, SGLang’s significant memory footprint made it impossible to start training. This was a conceptual baseline and was never implemented.
4.2: Offloading Weights to CPU and Relaunch Inference Engine
To address this, we offloaded training model weights to CPU after training, serializing them to disk. During the rollout phase, we relaunched the SGLang engine, loading weights from disk.
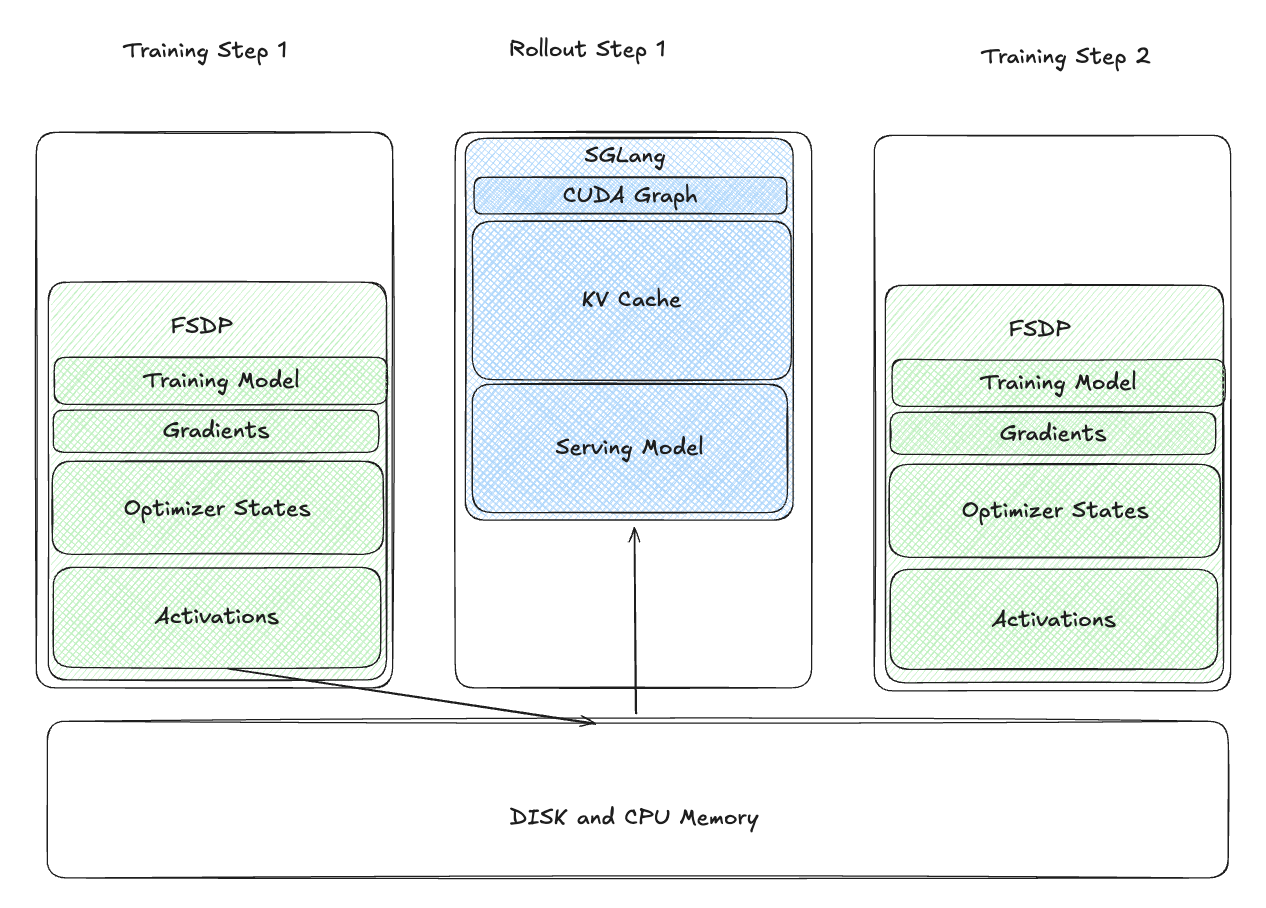
This reduced GPU memory usage during rollout but introduced significant delays:
- Slow Disk I/O: Loading weights from disk was time-consuming.
- Recapture CUDA Graph: Recapturing CUDA Graphs added overhead.
While this was an improvement, it was too slow for practical use.
4.3: Sleeping the Inference Engine
We explored keeping the CUDA Graph alive while freeing weights and KV cache memory during training. The challenge was that recreating these tensors broke CUDA Graph replay due to changes in virtual memory addresses.
Hence the goal can be rephrased to:
- Free physical memory during training to allocate space.
- Reallocate GPU memory for weights and KV cache at the same virtual memory addresses during rollout.
The SGLang RL team (credit to Tom) developed the torch_memory_saver library 2, enabling memory pausing and resuming while preserving CUDA Graph compatibility.
Here’s how it works:
import torch_memory_saver
memory_saver = torch_memory_saver.torch_memory_saver
# Create tensors in a pausable region
with memory_saver.region():
pauseable_tensor = torch.full((1_000_000_000,), 100, dtype=torch.uint8, device='cuda')
# Pause to free CUDA memory
memory_saver.pause()
# Resume to reallocate memory at the same virtual address
memory_saver.resume()
Implementation Using CUDA Virtual Memory APIs
Before CUDA 10.2, memory management relied on cudaMalloc, cudaFree, and cudaMemcpy, which lacked control over virtual memory addresses. CUDA 10.23 introduced APIs for fine-grained virtual memory management:
cuMemCreate: Creates a physical memory handle.cuMemAddressReserve: Reserves a virtual address range.cuMemMap: Maps a physical memory handle to a virtual address range.
These APIs enabled a custom memory allocator to preserve virtual memory addresses. And in SGLang and verl system, we utilized LD_PRELOAD 4 to replace the default cuda malloc and free with our custom allocator.
Modified CUDA Malloc
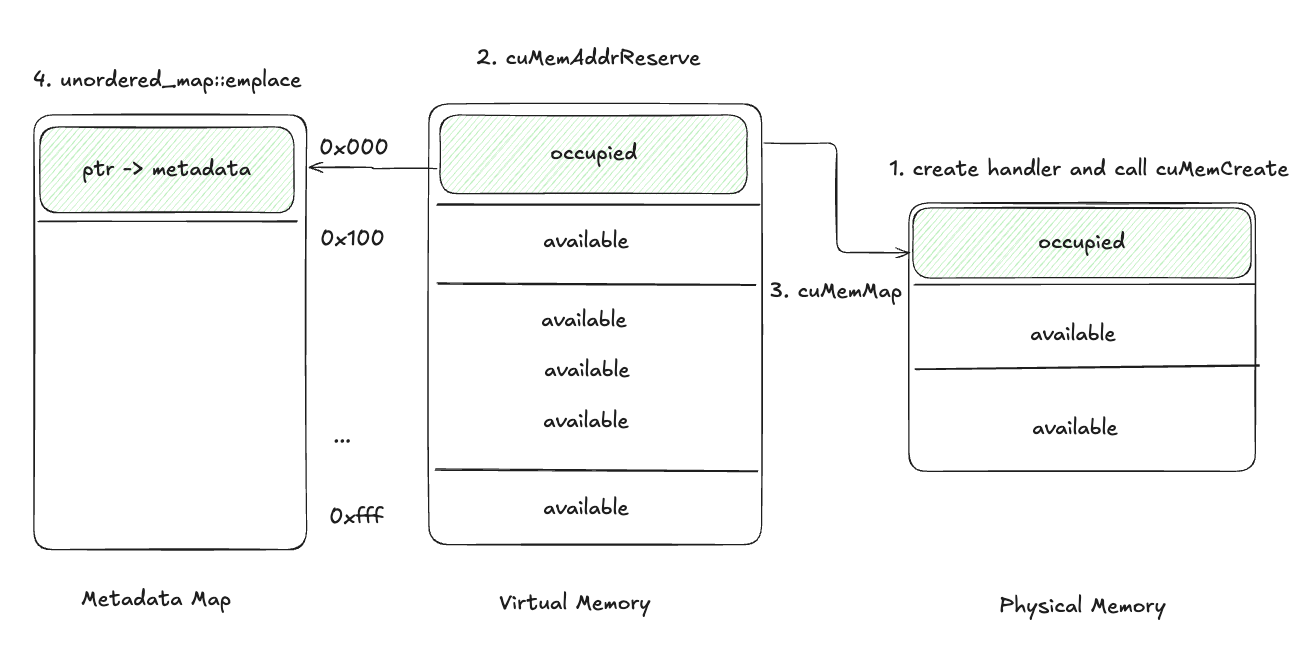
- Create a
CUmemGenericAllocationHandleand allocate physical memory withcuMemCreate, the handler contains the properties of the memory to allocate, like where is this memory physically located or what kind of shareable handles should be available. 3 - Reserve a virtual address range using
cuMemAddressReserve. - Map the physical memory to the virtual address using
cuMemMap. - Store the virtual memory pointer and physical memory handle in a Metadata Map.
Pausing Tensors
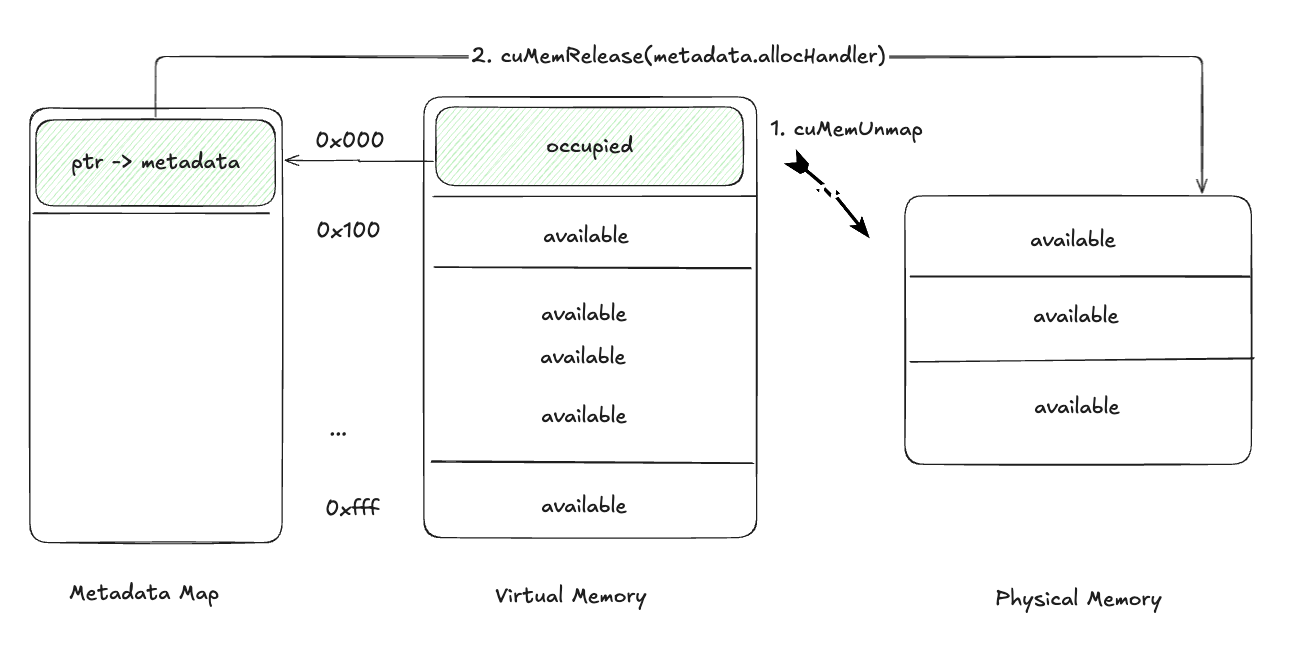
- Unmap memory from the virtual address range using
cuMemUnmap - Retrieve the physical memory handle from the Metadata Map and free it with
cuMemRelease.
This releases physical memory while retaining virtual addresses.
Resuming Tensors
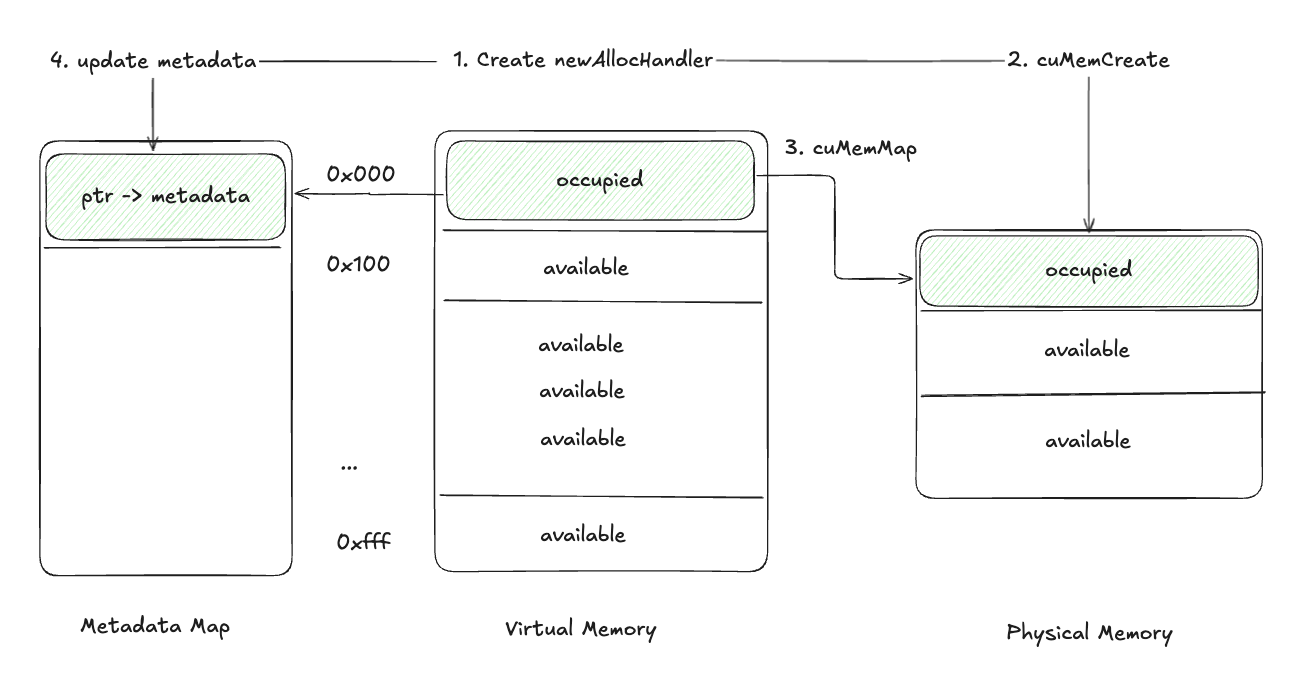
- Create a new physical memory handle with
cuMemCreate. - Allocate physical memory using
cuMemAlloc. - Map the new physical memory to the stored virtual address with
cuMemMap. - Update the Metadata Map with the new handle.
Until now, we have a pretty decent solution for the memory challenge.
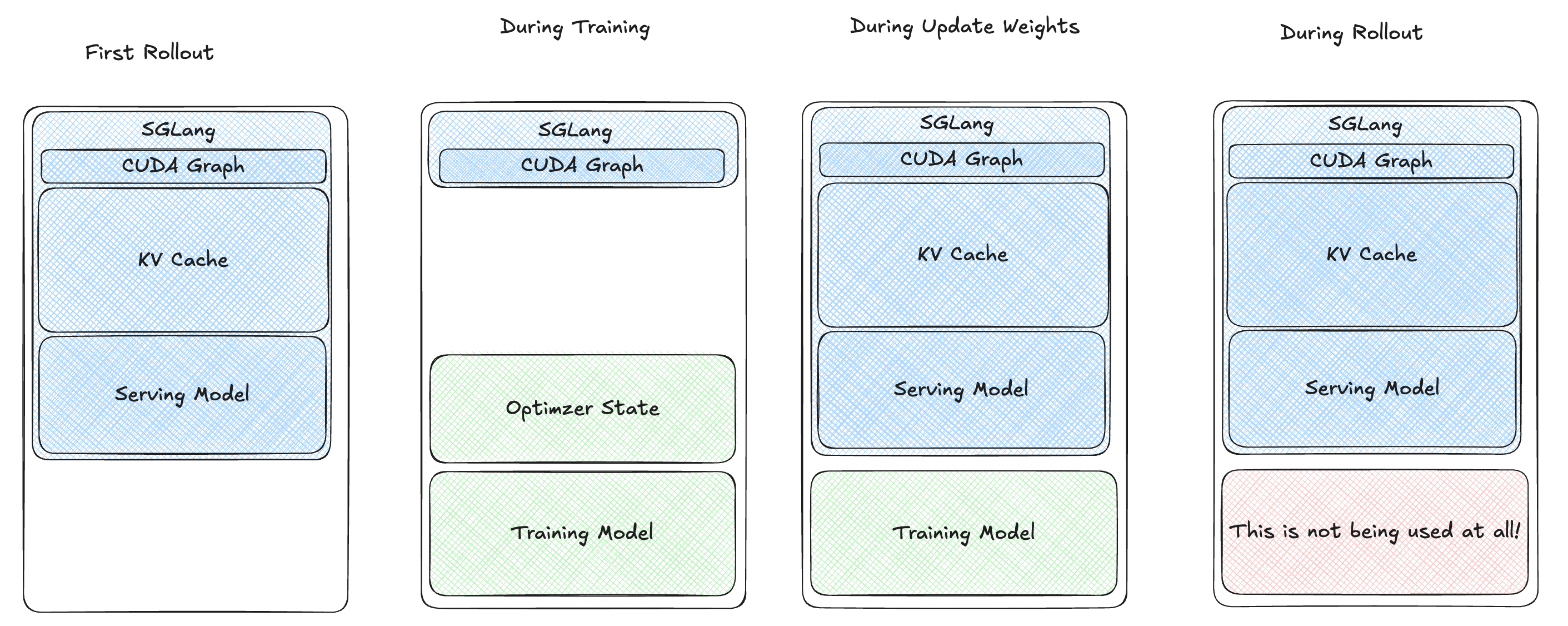
Weight Loading Optimization
To address slow weight loading, we avoided disk serialization. Instead, we loaded training model weights onto the GPU and updated the rollout engine’s weights via CUDA Inter-Process Communication. This reduced the training-to-rollout switch time significantly (e.g., <0.5s for a 7B model).
4.4: Multi-Stage Awake
Despite these improvements, our users reported Out-of-Memory (OOM) errors during training-rollout switches with larger models or high KV cache ratios (>0.7). We identified wasted memory during the resume process (red block in the above diagram). To optimize, we split the resume process into stages:
- Load training model weights onto the GPU.
- Resume the inference model weights.
- Sync weights.
- Offload the training model.
- Resume the KV cache for rollout.
Initially, torch_memory_saver’s singleton design didn’t support selective pausing/resuming of memory regions. We explored two solutions:
- Multiple
torch_memory_saverinstances. - A tag-based pause/resume API.
We chose the tag-based approach for minimal changes to SGLang’s codebase, which relied heavily on the singleton design. You can find both implementations in the RFC for implementation details.
Tag-Based Memory Management
We added a tag parameter to tensor metadata, enabling selective pausing/resuming.
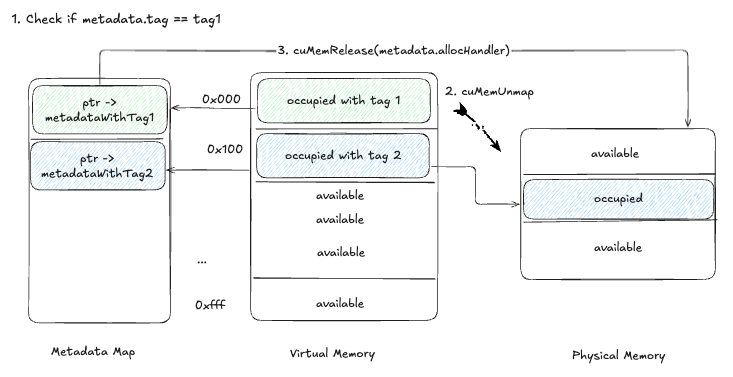
Pause Process:
- Check each tensor’s metadata for a matching tag.
- If matched, unmap the memory with
cuMemUnmap. - Free the physical memory with
cuMemRelease.
New Interface:
import torch_memory_saver
memory_saver = torch_memory_saver.torch_memory_saver
# Create tensors with specific tags
with torch_memory_saver.region(tag="weights"):
tensor1 = torch.full((5_000_000_000,), 100, dtype=torch.uint8, device='cuda')
with torch_memory_saver.region(tag="kv_cache"):
tensor2 = torch.full((5_000_000_000,), 100, dtype=torch.uint8, device='cuda')
# Pause and resume selectively
torch_memory_saver.pause("weights")
torch_memory_saver.pause("kv_cache")
torch_memory_saver.resume("weights")
# Sync weights and offload training model
torch_memory_saver.resume("kv_cache")
Multi-Stage Resume Process:
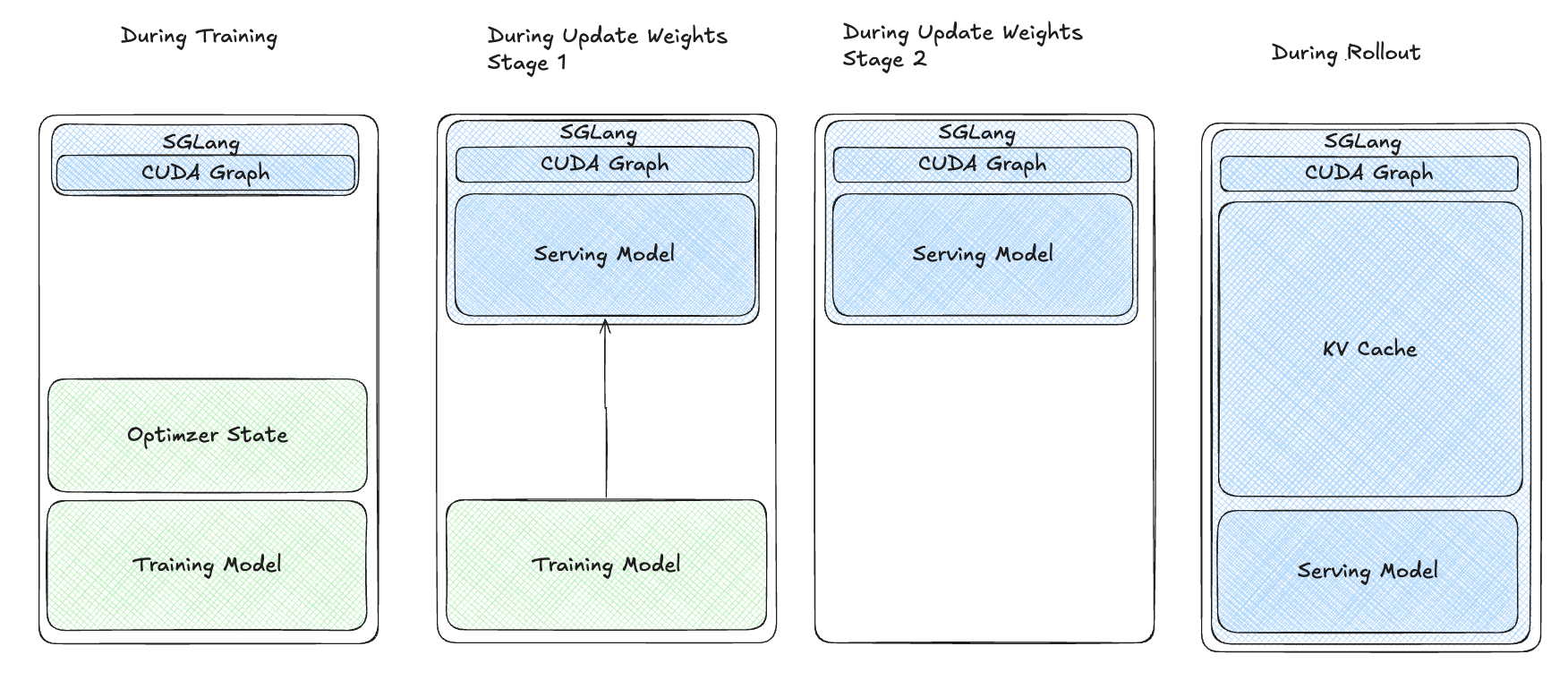
This approach minimized memory waste, resolved OOM issues, and improved efficiency for large models and high KV cache ratios.
5. Conclusion
Through the optimizations outlined in this journey, we successfully enabled training of Qwen 32B with a 0.9 KV cache memory ratio on 8 H200 GPUs—a feat that was initially unattainable. This blog post summarizes the SGLang RL team’s memory optimization efforts, offering insights into efficient memory management for reinforcement learning (RL) training. We hope it serves as a valuable resource for understanding and tackling similar challenges.
6. Acknowledgments
We extend our gratitude to the SGLang RL Team and verl Team, with special thanks to Tom for developing the compact yet powerful torch_memory_saver library and laying the groundwork for verl rollout with SGLang and Chenyang for leading the SGLang RL initiatives and providing critical guidance and support.