How to Calculate LLM Model Parameter Size - Dense Model
This guide explains how to calculate the parameter size of a dense large language model (LLM) using its architecture and configuration file. We’ll use the Qwen3-32B model as an example to demonstrate the process.
1. Understand the Model Architecture
To calculate a model’s parameter size, you first need to understand its architecture. Initially, I considered technical reports as a primary source, but for models like Qwen3, which inherit the Llama architecture, these reports may lack detailed implementation specifics. Instead, reviewing the model’s code in popular repositories provides deeper insight.
For Llama Model architecuture, we can refer to the
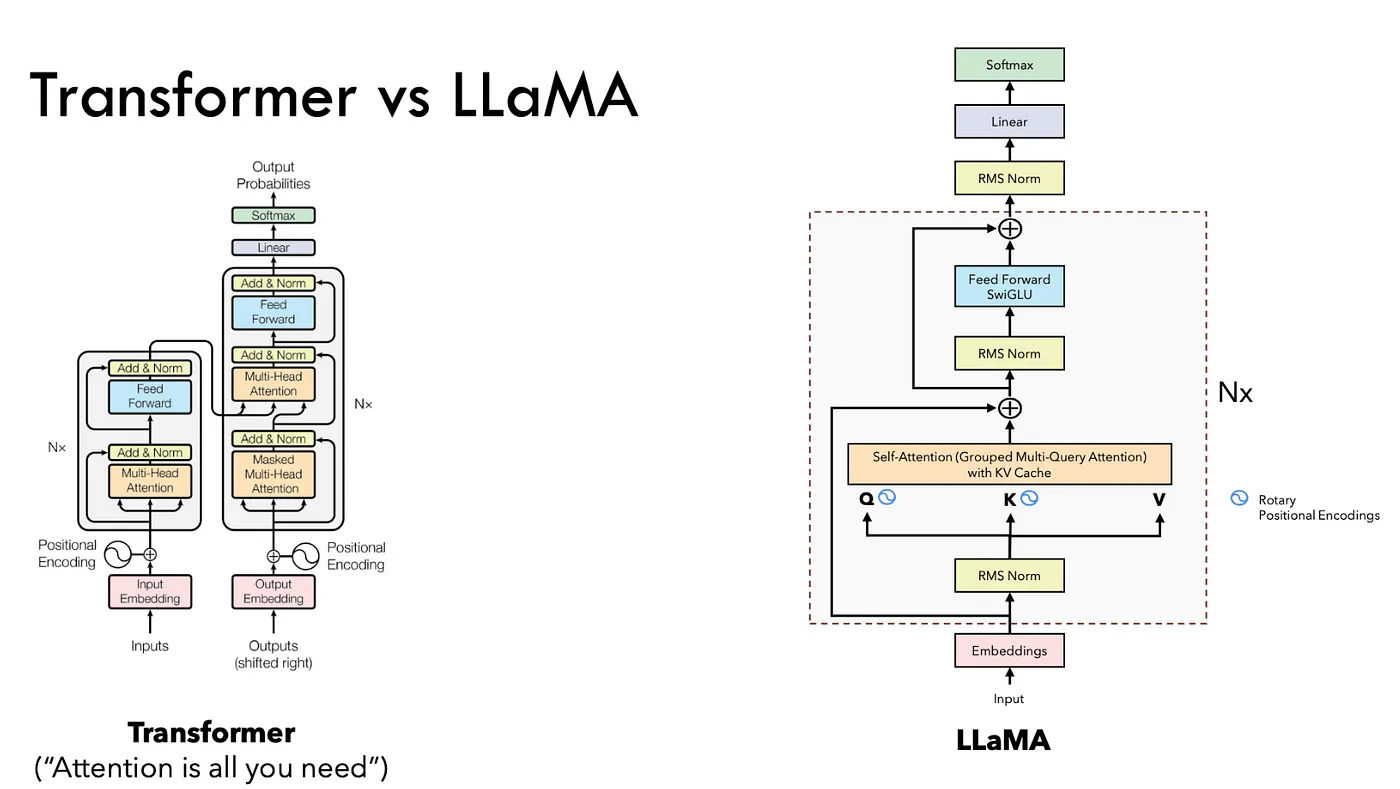
For Qwen3 detailed implementation, which follows the Llama architecture, you can refer to the following implementations:
- Huggingface Qwen3 Dense Model Implementation: Link
- SGLang Qwen3 Dense Model Implementation: Link
- vLLM Qwen3 Dense Model Implementation: Link
2. Extract Key Parameters from config.json
The model’s config.json file, available on the Qwen3-32B Hugging Face model card, contains critical parameters for calculating the model’s size.
| Parameter | Value | Description |
|---|---|---|
vocab_size | 151936 | Size of the vocabulary |
hidden_size | 5120 | Hidden dimension size |
num_hidden_layers | 64 | Number of transformer layers |
num_attention_heads | 64 | Number of attention heads |
num_key_value_heads | 8 | Number of key-value heads (for GQA) |
intermediate_size | 25600 | Size of the feed-forward network |
head_dim | 128 | Dimension of each attention head |
3. Calculate the model Parameter Size
Using the Llama-based architecture and the parameters from config.json, we can compute the total number of parameters in Qwen3-32B. The model consists of an embedding layer, transformer layers (with self-attention and MLP components), and a language model head. Below is the breakdown:
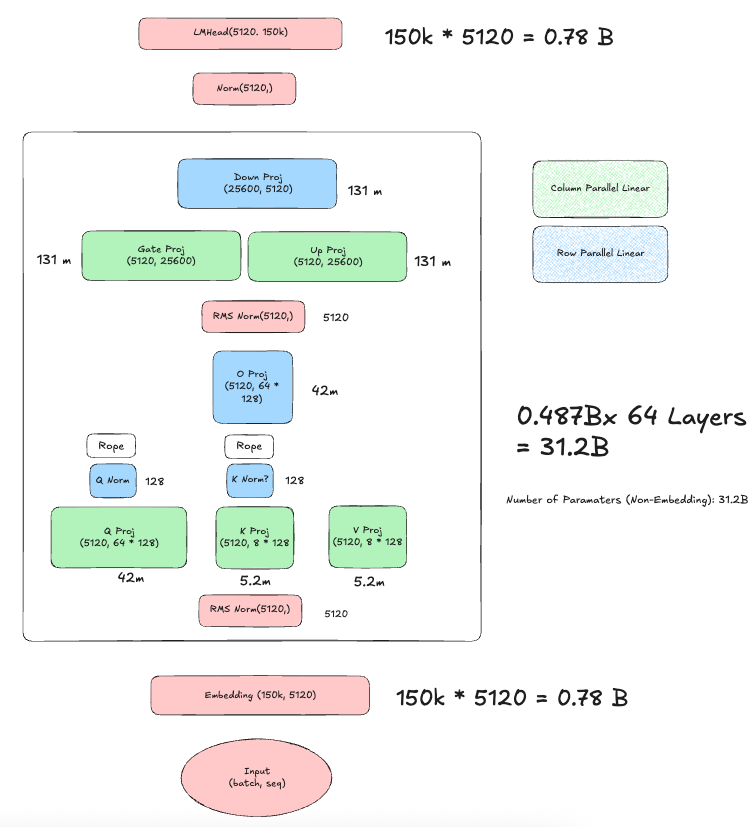
- Embedding Layer
- Parameters:
vocab_size × hidden_size - Calculation:
151936 × 5120 = 777,724,288 ≈ 0.78B
- Parameters:
-
Transformer Layers (64 × Qwen3DecoderLayer)
Each of the 64 transformer layers includes self-attention and MLP components, with layer normalization parameters (which are negligible in size).
- Self-Attention (94.4M per layer)
- Q Projection:
hidden_size × (num_attention_heads × head_dim)5120 × (64 × 128) = 5120 × 8192 = 41,943,040 ≈ 42M
- K Projection:
hidden_size × (num_key_value_heads × head_dim)5120 × (8 × 128) = 5120 × 1024 = 5,242,880 ≈ 5.2M
- V Projection:
hidden_size × (num_key_value_heads × head_dim)5120 × (8 × 128) = 5,242,880 ≈ 5.2M
- O Projection:
(num_attention_heads × head_dim) × hidden_size(64 × 128) × 5120 = 8192 × 5120 = 41,943,040 ≈ 42M
- Q/K Norms:
head_dim = 128(negligible, ignored) - Total per layer:
42M + 5.2M + 5.2M + 42M = 94.4M - Across 64 layers:
94.4M × 64 = 6,041.6M ≈ 6.04B
- Q Projection:
- MLP (393M per layer)
- Gate Projection:
hidden_size × intermediate_size5120 × 25600 = 131,072,000 ≈ 131M
- Up Projection:
hidden_size × intermediate_size5120 × 25600 = 131,072,000 ≈ 131M
- Down Projection:
intermediate_size × hidden_size25600 × 5120 = 131,072,000 ≈ 131M
- Total per layer:
131M + 131M + 131M = 393M - Across 64 layers:
393M × 64 = 25,152M ≈ 25.15B
- Gate Projection:
- Layer Norms:
hidden_size = 5120per norm (input and post-attention, negligible, ignored) - Total per layer:
94.4M + 393M = 487.4M - Across 64 layers:
487.4M × 64 ≈ 31.2B
- Self-Attention (94.4M per layer)
- Output Layer Norm
- Parameters:
hidden_size = 5120(negligible, ignored)
- Parameters:
- Language Model Head
- Parameters:
hidden_size × vocab_size - Calculation:
5120 × 151936 = 777,724,288 ≈ 0.78B
- Parameters:
Total Parameters:
0.78B (Embedding) + 31.2B (Transformer Layers) + 0.78B (LM Head) ≈ 32.76B
4. Verify the Calculation
The Qwen3-32B model card reports a total parameter count of 32.8B, with non-embedding parameters totaling 31.2B. These figures align closely with our calculations, confirming their accuracy.

5. Programatic Calculation
To automate the parameter calculation, you can use a Python script with the Hugging Face transformers library. The script below loads the Qwen3-32B model and tallies parameters by component:
from transformers import AutoModelForCausalLM
import torch
from collections import defaultdict
model_path = "/shared/public/elr-models/Qwen/Qwen2.5-7B-Instruct/52e20a6f5f475e5c8f6a8ebda4ae5fa6b1ea22ac"
model = AutoModelForCausalLM.from_pretrained(
model_path,
torch_dtype=torch.float16,
device_map="auto",
trust_remote_code=True
)
print(model)
# Dictionary to store parameter counts per submodule
param_groups = defaultdict(int)
# Traverse all named parameters
for name, param in model.named_parameters():
if not param.requires_grad:
continue
if "embed_tokens" in name:
param_groups["Embedding"] += param.numel()
elif "lm_head" in name:
param_groups["LM Head"] += param.numel()
elif ".self_attn.q_proj" in name:
param_groups["Attention/q_proj"] += param.numel()
elif ".self_attn.k_proj" in name:
param_groups["Attention/k_proj"] += param.numel()
elif ".self_attn.v_proj" in name:
param_groups["Attention/v_proj"] += param.numel()
elif ".self_attn.o_proj" in name:
param_groups["Attention/o_proj"] += param.numel()
elif ".self_attn.q_norm" in name:
param_groups["Attention/q_norm"] += param.numel()
elif ".self_attn.k_norm" in name:
param_groups["Attention/k_norm"] += param.numel()
elif ".mlp.gate_proj" in name:
param_groups["MLP/gate_proj"] += param.numel()
elif ".mlp.up_proj" in name:
param_groups["MLP/up_proj"] += param.numel()
elif ".mlp.down_proj" in name:
param_groups["MLP/down_proj"] += param.numel()
elif "input_layernorm" in name:
param_groups["LayerNorm/input"] += param.numel()
elif "post_attention_layernorm" in name:
param_groups["LayerNorm/post_attention"] += param.numel()
elif name.startswith("model.norm"):
param_groups["LayerNorm/final"] += param.numel()
elif "rotary_emb" in name:
param_groups["RotaryEmbedding"] += param.numel()
else:
param_groups["Other"] += param.numel()
total_params = sum(p.numel() for p in model.parameters())
print(f"Total params: {total_params / 1e9:.2f}B")
Sample Output
Qwen3ForCausalLM(
(model): Qwen3Model(
(embed_tokens): Embedding(151936, 5120)
(layers): ModuleList(
(0-63): 64 x Qwen3DecoderLayer(
(self_attn): Qwen3Attention(
(q_proj): Linear(in_features=5120, out_features=8192, bias=False)
(k_proj): Linear(in_features=5120, out_features=1024, bias=False)
(v_proj): Linear(in_features=5120, out_features=1024, bias=False)
(o_proj): Linear(in_features=8192, out_features=5120, bias=False)
(q_norm): Qwen3RMSNorm((128,), eps=1e-06)
(k_norm): Qwen3RMSNorm((128,), eps=1e-06)
)
(mlp): Qwen3MLP(
(gate_proj): Linear(in_features=5120, out_features=25600, bias=False)
(up_proj): Linear(in_features=5120, out_features=25600, bias=False)
(down_proj): Linear(in_features=25600, out_features=5120, bias=False)
(act_fn): SiLU()
)
(input_layernorm): Qwen3RMSNorm((5120,), eps=1e-06)
(post_attention_layernorm): Qwen3RMSNorm((5120,), eps=1e-06)
)
)
(norm): Qwen3RMSNorm((5120,), eps=1e-06)
(rotary_emb): Qwen3RotaryEmbedding()
)
(lm_head): Linear(in_features=5120, out_features=151936, bias=False)
)
MLP/gate_proj : 8388.61M params
MLP/up_proj : 8388.61M params
MLP/down_proj : 8388.61M params
Attention/q_proj : 2684.35M params
Attention/o_proj : 2684.35M params
Embedding : 777.91M params
LM Head : 777.91M params
Attention/k_proj : 335.54M params
Attention/v_proj : 335.54M params
LayerNorm/input : 0.33M params
LayerNorm/post_attention : 0.33M params
Attention/q_norm : 0.01M params
Attention/k_norm : 0.01M params
LayerNorm/final : 0.01M params
Total params: 32.76B
The programmatic results match the manual calculation, reinforcing confidence in the approach.
6. Conclusion
This guide demonstrated how to calculate the parameter size of a dense LLM like Qwen3-32B using its architecture and config.json file. By breaking down the model into its components—embedding layer, transformer layers, and language model head—we computed a total of approximately 32.76 billion parameters, consistent with the official model card. Additionally, a Python script was provided to automate this process, offering a reusable tool for analyzing other models.
This approach can be applied to any transformer-based model by adapting the architecture-specific calculations and configuration parameters.
7. Questions Left Unanswered
From the guide, we actually left a few questions unanswered:
- Why the
num_heads != num_key_value_heads? (hint: Group Query Attention) - Why some of the weight layers are Column Parallel and some are Row Parallel? (hint: Model Parallelism, Avoid Communication Overhead)
- What is RMS Norm?
- What is Gate and Up Projection?
I’ll leave these questions for future posts.